
初识 Hadoop
Hadoop 是什么
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和海量存储。
Hadoop 官网的原话是:The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing。
意思是 Hadoop 是一个可靠的、可扩展的、分布式的计算框架。
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称 HDFS。HDFS 有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。Hadoop 的框架最核心的设计就是:HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,而 MapReduce 则为海量的数据提供了计算。
Hadoop 起源
总结来说,Hadoop 起源于 Google 的三篇论文,分别是:
- GFS:Google 的分布式文件系统 Google File System;
- MapReduce:Google 的 MapReduce 开源分布式并行计算框架;
- BigTable:一个大型的分布式数据库。
所以,Hadoop 的演变关系是:
GFS –> HDFS
Google MapReduce –> Hadoop MapReduce
BigTable –> HBase
Hadoop 的优势(4 高)
高可靠性:Hadoop 底层维护了多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失;
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点;
高效性:在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度;
高容错性:能够自动将失败的任务重新分配。
Hadoop 的组成
官网原话为:
The project includes these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
- Hadoop Ozone: An object store for Hadoop.
即:
- Hadoop Common:这是可以支持其他 Hadoop 组件的公用的工具;
- Hadoop Distributed File System (HDFS):这是一个可以给应用程序提供高吞吐量的 Hadoop 的分布式文件系统(分布式文件系统);
- Hadoop YARN:这是一个对于作业调度以及集群资源管理的一个框架(分布式资源调度框架);
- Hadoop MapReduce:这是一个基于 YARN 的并行处理的大数据框架系统(分布式计算框架);
- Hadoop Ozone:一个对于 Hadoop 的对象存储。
注:Hadoop 1.X 和 Hadoop 2.X 的区别主要是相较于Hadoop 2.X,Hadoop 1.X 没有 YARN,资源调度和计算均是 MapReduce 进行处理,耦合性较强。
HDFS 概述
HDFS 优点:扩展性好,容错性高,能存储海量数据。
HDFS 将文件切分成指定大小的数据块并以多个副本的形式存储在多台机器上,如图:
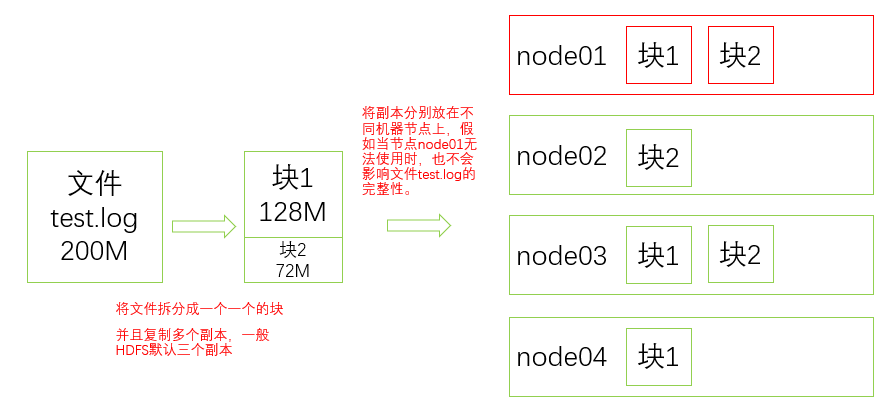
假设块的默认大小为 128M,则文件 test.log 将被切分为 128M+72M 两个数据块,并将两个数据块及副本分布式存储到各个机器节点上,当某个机器节点无法访问时也并不影响文件 test.log 的完整性。
另外,关于数据的切分、多副本以及容错等操作对于用户而言是透明的,用户是不知情的。
MapReduce 概述
MapReduce 优点:扩展性好,容错性高,海量数据离线处理。
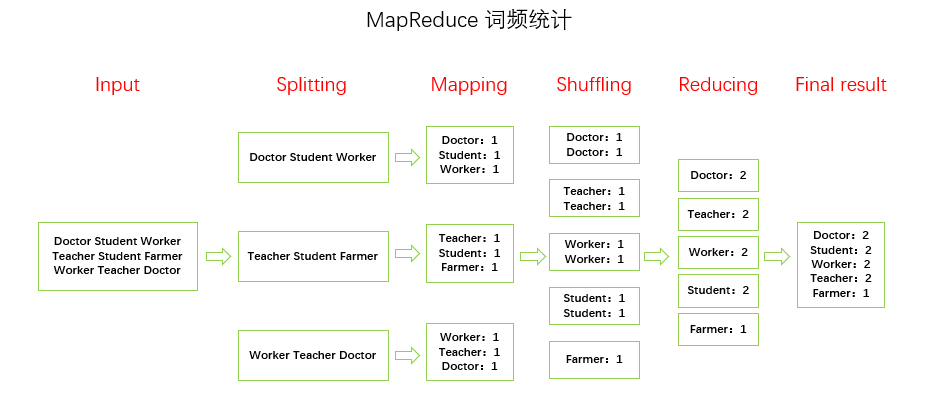
MapReduce 将计算过程分为两个阶段:Map 和 Reduce:
- Map 阶段并行处理输入数据;
- Reduce 阶段对 Map 结果进行汇总。
以一个词频统计为例来了解 Map 和 Reduce 分别处于哪个阶段,如图:
YARN 概述
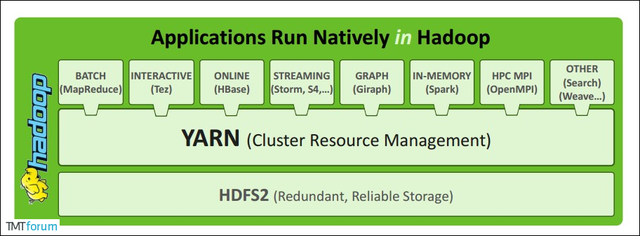
YARN 优点:扩展性好,容错性高,多框架资源统一调度。
多框架资源统一调度是指其他框架也能在 YARN 上跑,例如Spark、HBase。
广义的 Hadoop 和 狭义的 Haddop
Hadoop 广义上来说是指 Hadoop 的生态圈,即 Hadoop 是一个生态系统,生态系统中的每一个子系统只解决某一个特定的问题域,是多个小而精的小系统组合而成的,如下图:
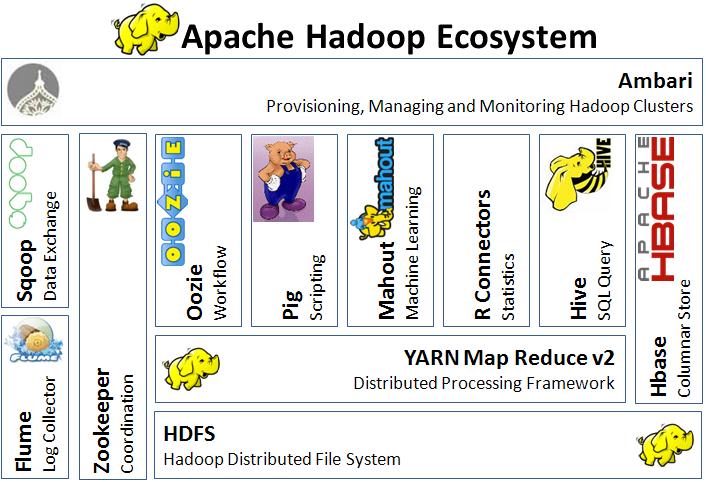
而狭义上的 Hadoop 仅仅指的是 Hadoop 框架内部分,即 Hadoop 是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台。
文档信息
- 本文作者:Bin Tu
- 本文链接:https://plandocheckaction.github.io/2020/07/19/BigData2-MeetHadoop/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)