
Hadoop 环境搭建(一)
新建虚拟机及 Linux 环境搭建
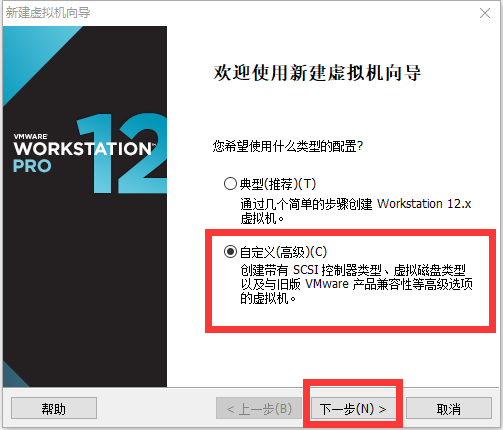
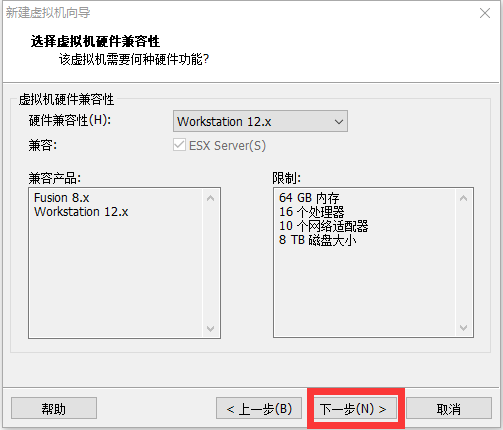
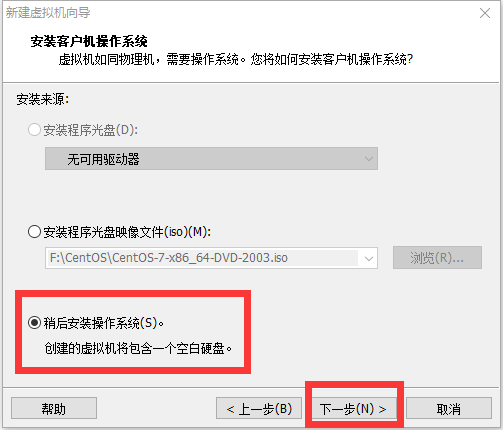
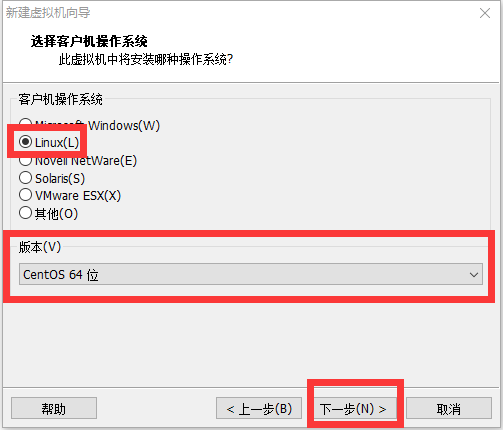
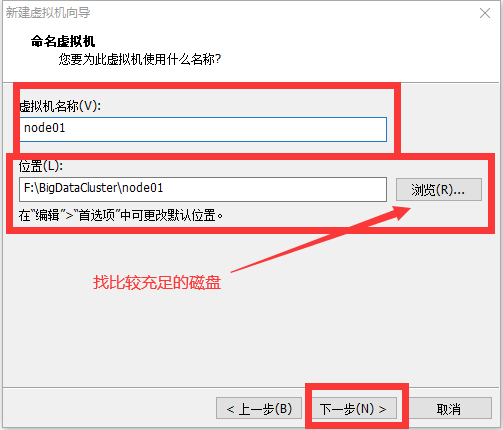
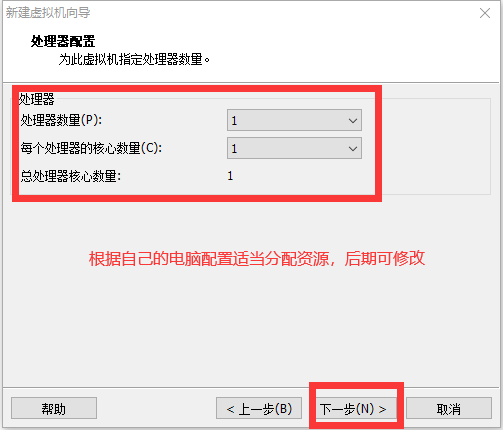
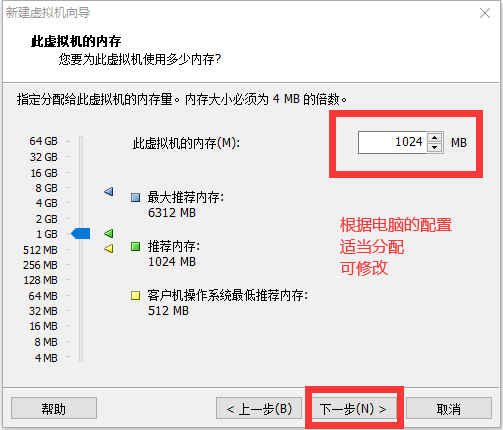
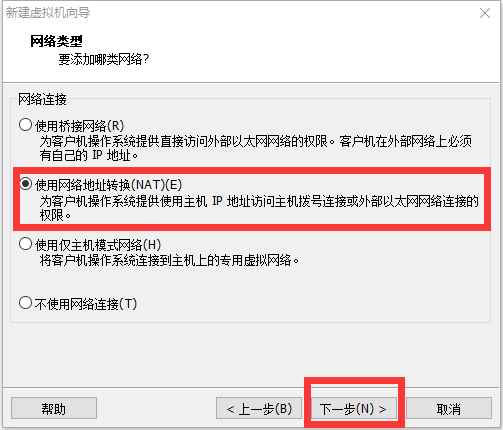
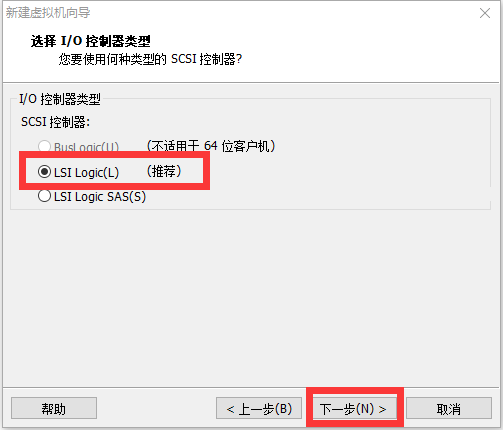
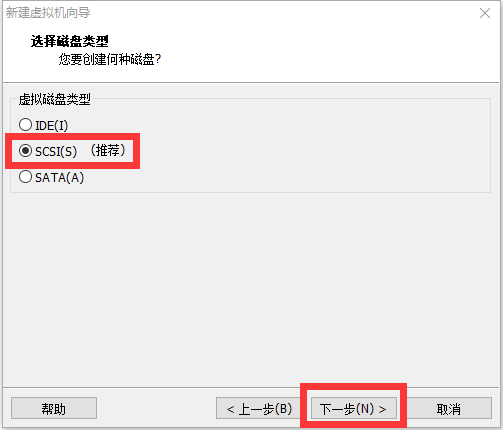

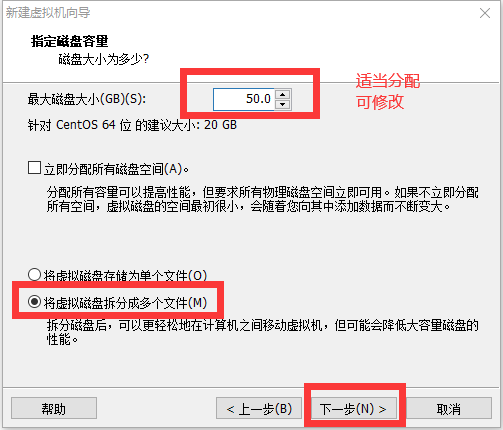
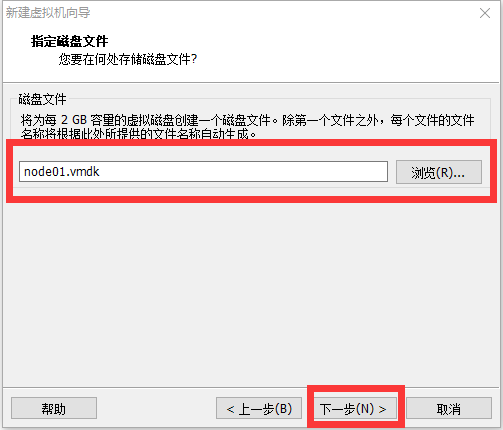
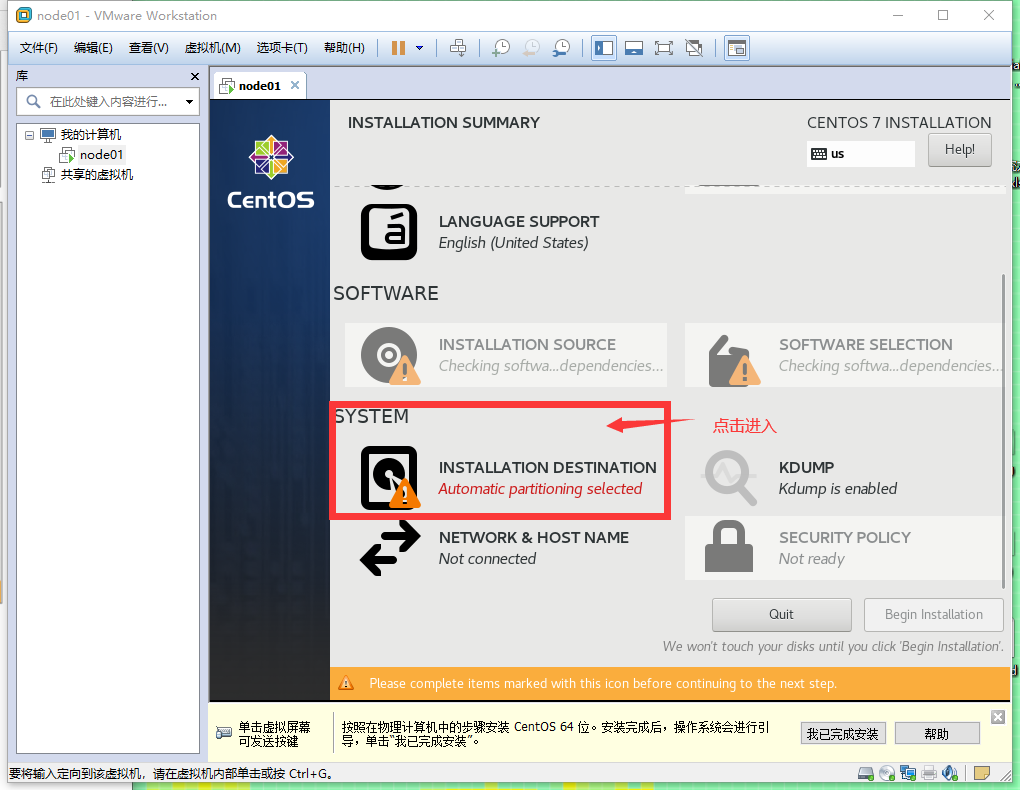
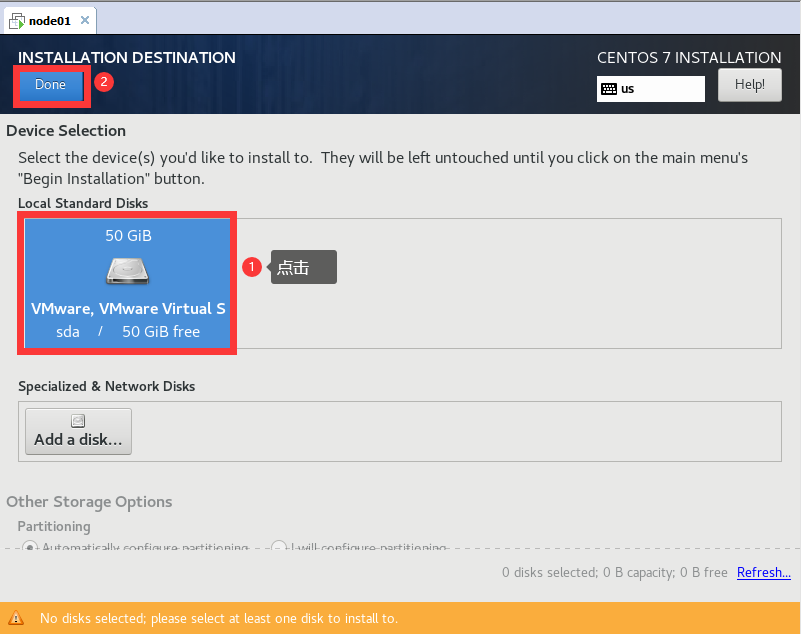
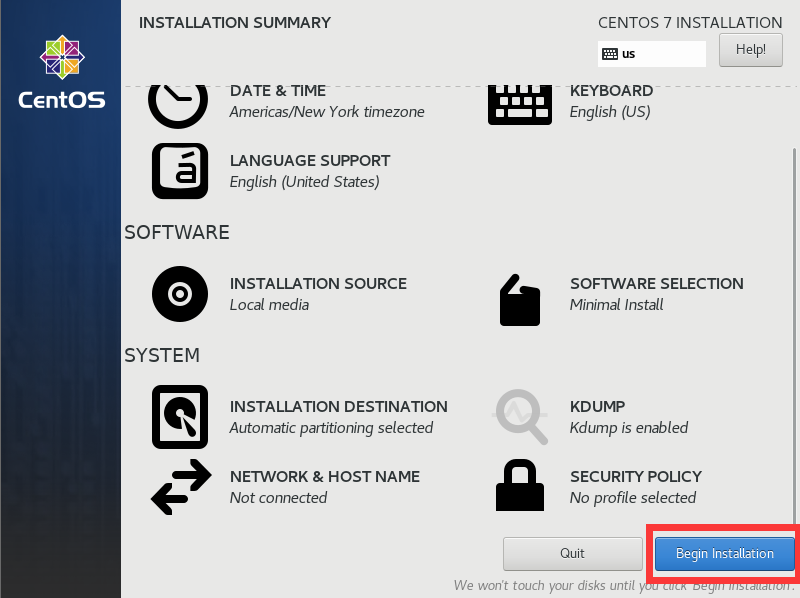
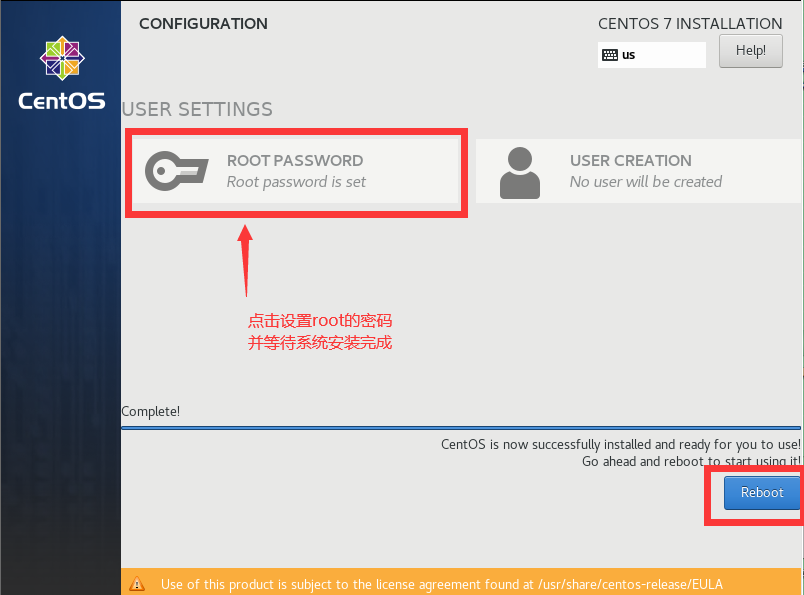
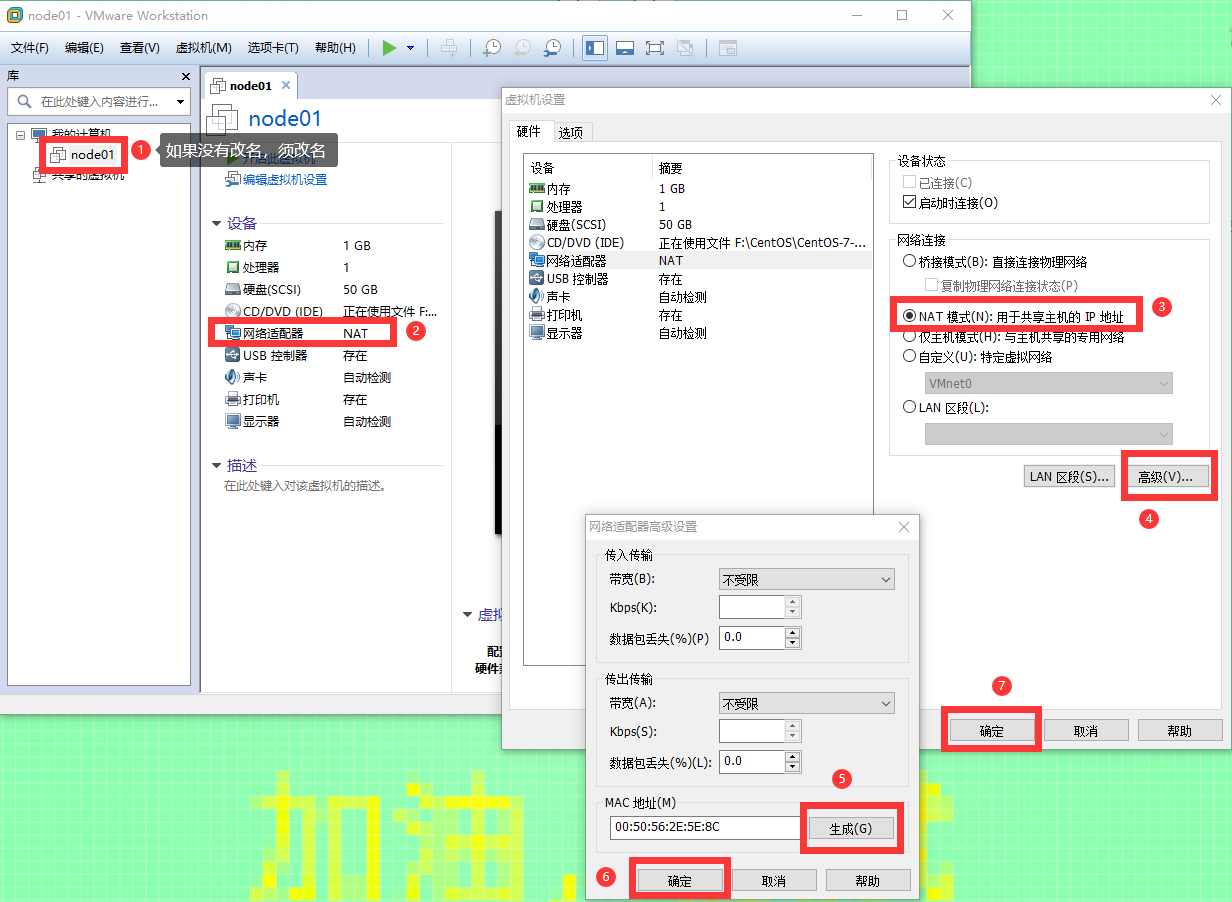
修改网络配置
进入 CentOS7 操作系统,输入命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改两处:
BOOTPROTO=static
ONBOOT=yes
添加下述代码:
IPADDR=192.168.87.100
GATEWAY=192.168.87.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
注:以下三处地方的前三位要相同。 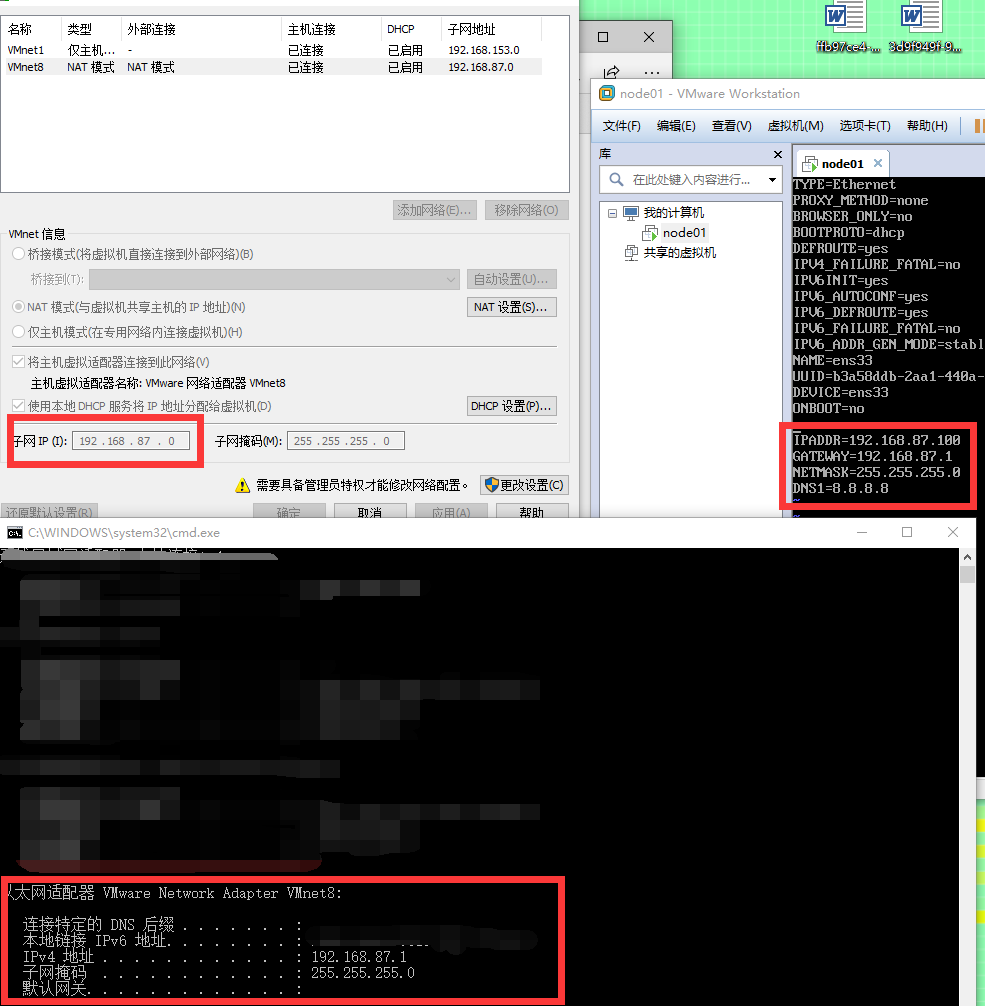
修改后重启操作系统,即可连通内网,要连通外网的话须将防火墙关闭。
shutdown -h now
替换国内 yum 源
这个方法我在Linux 处理目录的常用命令讲过。
创建用户
添加用户并设置用户密码:
useradd 用户名
passwd 用户名
为普通用户添加权限:
- 进入文件:
vi /etc/sudoers - 在文件中添加所有权限
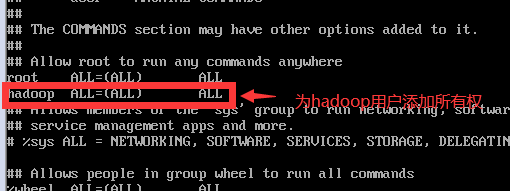
注1:普通用户添加完所有权限后,后面的操作均是以普通用户的账号去操作,当普通用户需要管理员权限时,在命令前加 sudo 即可。
注2:完全分布式的搭建要求各个节点创建的普通用户名要相同,密码也要相同。
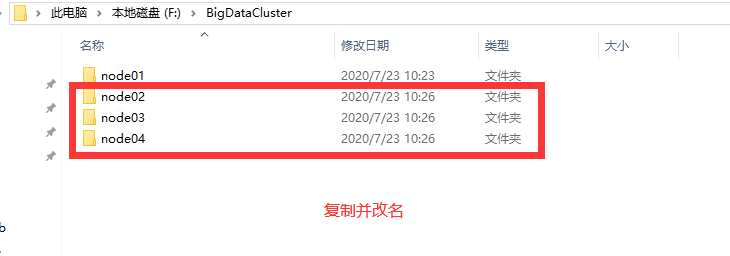
复制多个节点
进入节点目录,复制节点并修改文件夹名称,我这里复制了三个节点,总共四个服务器节点。
进入复制的每个节点的文件夹内,双击打开 .vmx 的文件:
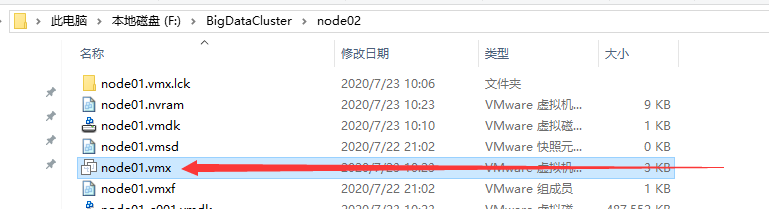
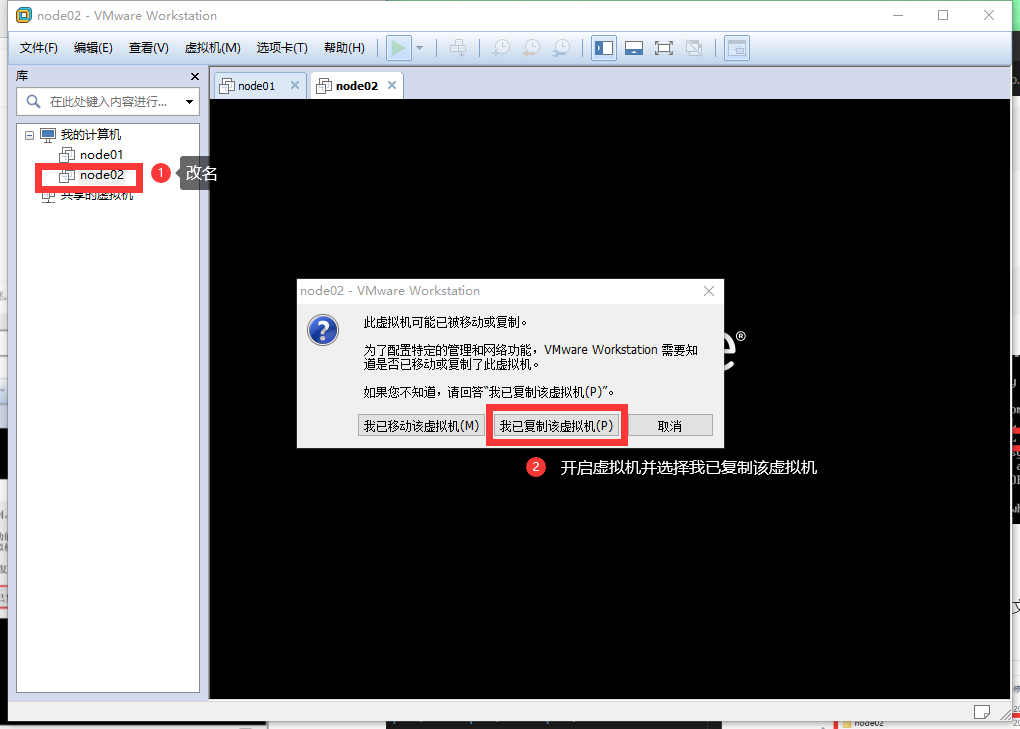
然后按照下图再来一遍:
再重新修改网络配置,方法如上。
注:我这边设置的四个节点的配置分别如下:
| IP | Host | CPU | Memory | Disk |
|---|---|---|---|---|
| 192.168.87.100 | hadoop01 | 1cores | 1G | 50G |
| 192.168.87.101 | hadoop02 | 1cores | 1G | 50G |
| 192.168.87.102 | hadoop03 | 1cores | 1G | 50G |
| 192.168.87.103 | hadoop04 | 1cores | 1G | 50G |
更改主机名
vi /etc/hostname
四个节点分别设置主机名为 hadoop01、hadoop02、hadoop03、hadoop04。
配置 hosts 文件
进入文件:
sudo vi /etc/hosts
将所有节点的 IP 地址映射均添加到每一个节点上:
192.168.87.100 hadoop01
192.168.87.101 hadoop02
192.168.87.102 hadoop03
192.168.87.103 hadoop04
关闭防火墙和 selinux
关闭防火墙:
# 查看防火墙状态
systemctl status firewalld.service
# 临时关闭防火墙
systemctl stop firewalld.service
# 设置开机不启动防火墙
systemctl disable firewalld.service
关闭 selinux:
# 永久关闭selinux
sudo vi /etc/selinux/config
# 将 SELINUX=enforcing 改为
SELINUX=disabled
设置启动级别
CentOS6 是通过修改 /etc/inittab 来修改默认运行级别的:
sudo vi /etc/inittab
但在 CentOS7 中,里面除了注释,什么也没有,当需要查看或修改启动级别时,可使用以下命令:
#查看默认运行级别的方式为
systemctl get-default
#设置默认运行级别的方式
systemctl set-default TARGET.target
这里我们要求是多用户启动,即启动级别为 3,multi-user.target。
CentOS7 中默认是 3,无需修改。
配置免密登录
所有节点均要配置免密登录。
第一步:四台服务器均生成公钥和私钥。
#在四台机器执行以下命令,生成公钥与私钥
cd ~
ssh-keygen -t rsa
执行该命令之后,要连续按三下回车键。
第二步:拷贝每台服务器的公钥到全部四台服务器上。
# 将四台机器的公钥拷贝到第一台服务器,四台服务器均执行命令:
ssh-copy-id hadoop01
# 将四台机器的公钥拷贝到第二台服务器,四台服务器均执行命令:
ssh-copy-id hadoop02
# 将四台机器的公钥拷贝到第三台服务器,四台服务器均执行命令:
ssh-copy-id hadoop03
# 将四台机器的公钥拷贝到第四台服务器,四台服务器均执行命令:
ssh-copy-id hadoop04
第三步:验证是否可以登录。
# 验证服务器是否均可以登录 hadoop01
ssh hadoop01
# 退出登录
exit
# 验证服务器是否均可以登录 hadoop02
ssh hadoop02
# 退出登录
exit
# 验证服务器是否均可以登录 hadoop03
ssh hadoop03
# 退出登录
exit
# 验证服务器是否均可以登录 hadoop04
ssh hadoop04
# 退出登录
exit
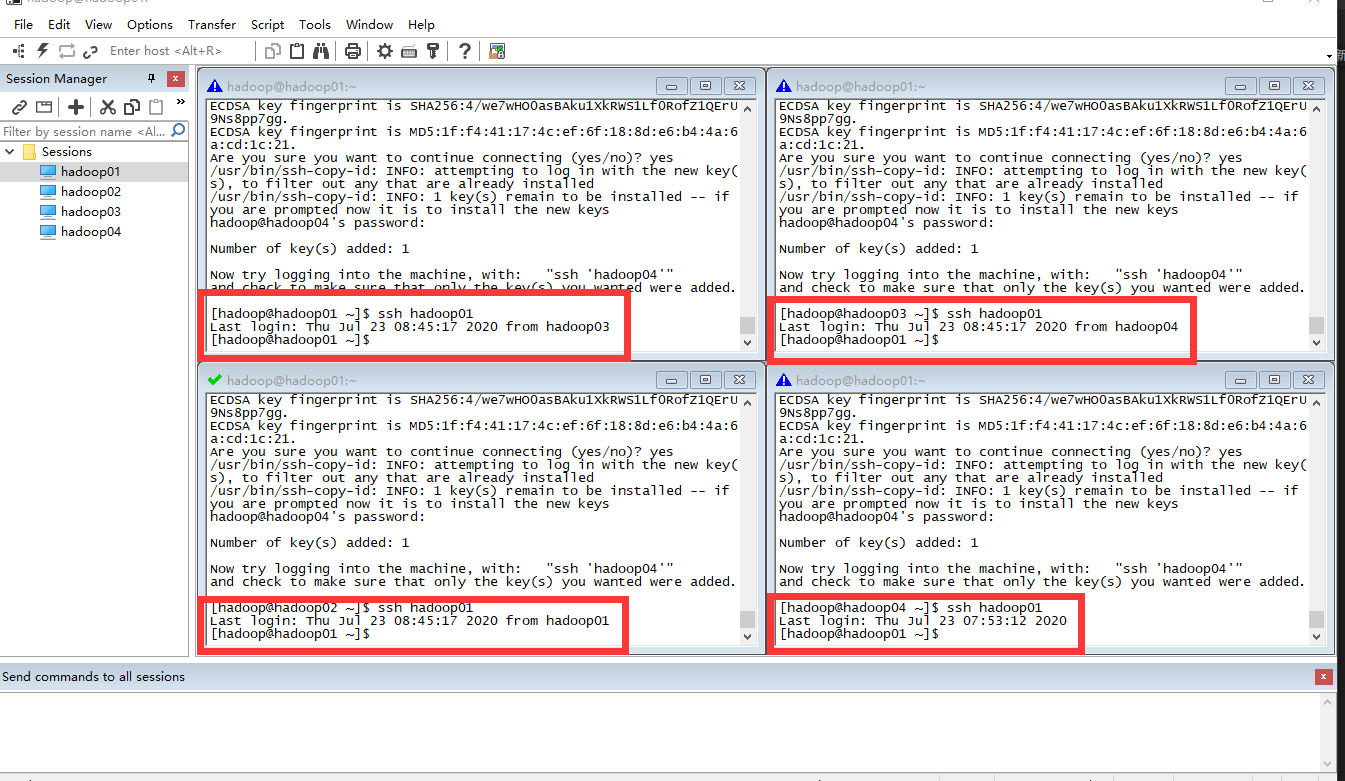
即各个节点均要做相互验证。
时间同步
当不能联网时,可以手动指定时间:
#查询服务器时间/时区
timedatectl
#设置时间
date -s 2020-07-23
#设置时区为Asia/Shanghai
timedatectl set-timezone Asia/Shanghai
当能联网时,找一个公网中的公用时间服务器即可:
#设置时区为Asia/Shanghai
timedatectl set-timezone Asia/Shanghai
#安装ntp服务
yum -y install ntp
#启动ntpd的服务
service ntpd start
#设置ntpd的服务开机启动
systemctl enable ntpd.service
#查看ntpd的服务是否启动
service ntpd status
然后设置定时任务,我这边用的是阿里的时间服务器,所以与阿里云服务器时钟相同:
crontab -e
*/1 * * * * /usr/sbin/ntpdate -u ntp4.aliyun.com;
配置成功后会经常弹出:You have new mail in /var/spool/mail/root 提示,可通过以下操作关闭邮件提示功能:
echo "unset MAILCHECK" >> /etc/profile
source /etc/profile
到此,完全分布式的 linux 集群环境就配置完成。
文档信息
- 本文作者:Bin Tu
- 本文链接:https://plandocheckaction.github.io/2020/07/23/BigData3-CentOS7ClusterSetup/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)