
Hadoop 环境搭建(二)
JDK 安装
下载 JDK 并解压: 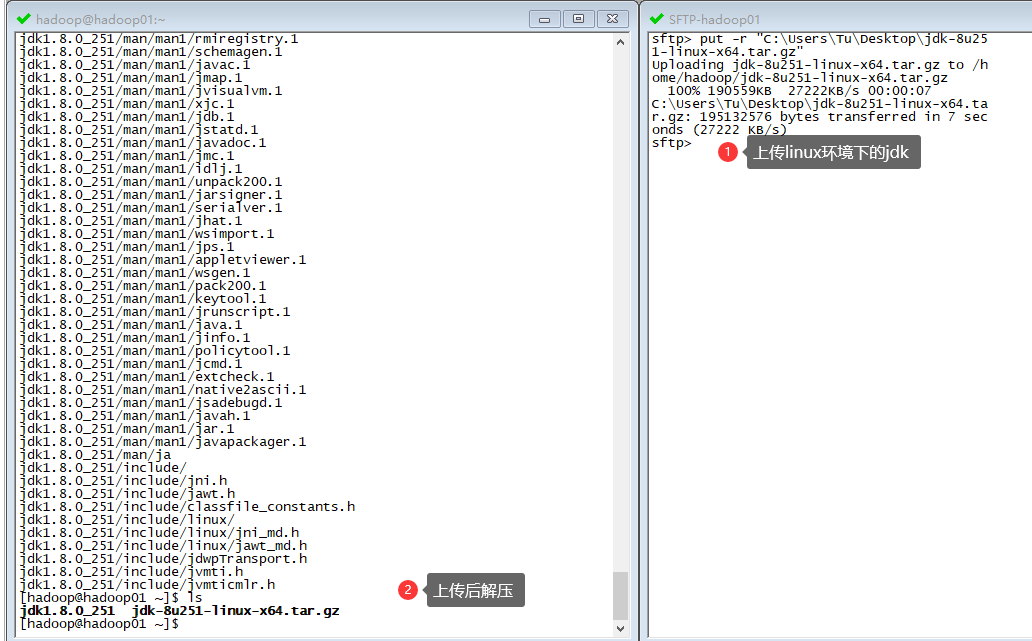
解压命令是:
tar -svzf 压缩包名
配置 JAVA 环境变量
vi /etc/profile
在最下面添加环境变量信息:
export JAVA_HOME=/home/hadoop/jdk1.8.0_251
export PATH=$PATH:$JAVA_HOME/bin
然后再输入命令:
source /etc/profile
至此,一台服务器上的 java 环境就配置好了。 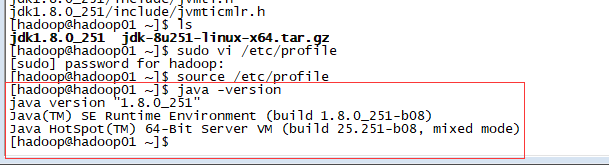
再配置其余三台服务器,由于其余三台服务器没有 java 文件,我们可以利用第一台上已安装的 java 文件复制过去,远程复制传输命令是:
scp -r jdk1.8.0_251 hadoop02:$pwd
scp -r jdk1.8.0_251 hadoop03:$pwd
scp -r jdk1.8.0_251 hadoop04:$pwd
最后在将其余三台服务器的环境变量配置就大功告成了。
Hadoop 安装
下载 hadoop 并解压,我这里用的是 hadoop2.7.7 的版本:
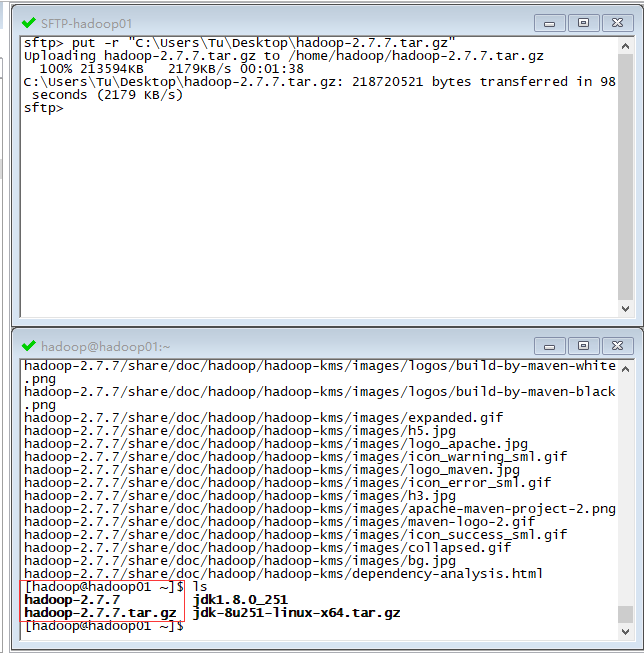
解压命令是:
tar -svzf 压缩包名
配置 Hadoop 环境变量
每台机器均执行以下操作:
vi /etc/profile
在最下面环境变量信息改为:
export JAVA_HOME=/home/hadoop/jdk1.8.0_251
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后再输入命令:
source /etc/profile
至此,Hadoop 的环境变量就配置好了。 
Hadoop 目录结构
我们进入到 Hadoop 文件夹内,可以看到 Hadoop 的整个目录结构:
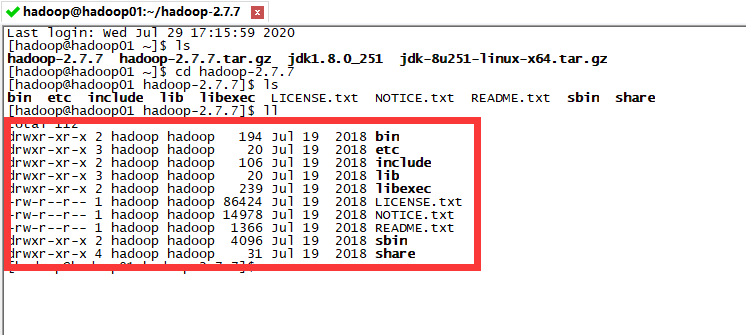
- bin:存放了一些我们以后会用到的服务,例如 hdfs(管理 hdfs 的)、hadoop(管理整个 hadoop 集群的)、yarn(管理资源调度的);
- etc:各种配置文件(后面需要修改);
- include:一些头文件,一般不需要去动它;
- lib:一些本地库;
- libexec:跟 lib 差不多;
- LICENSE.txt:许可证;
- NOTICE.txt:通知;
- README.txt:说明;
- sbin:存放了大量的 hadoop 启动/停止、集群的启动/停止的脚本命令;
- share:开发文档和一些案例。
Hadoop 运行模式
Hadoop 运行模式有三种:本地运行模式、伪分布式运行模式、完全分布式运行模式。
本地运行模式和伪分布式运行模式一般是学习和测试时用,真正开发时是用完全分布式运行模式。
本地运行模式和伪分布式运行模式的配置官网都写得很详细了,在此不作更细致的说明,官网文档点击此处!
修改配置文件
现在我们来仔细配置好完全分布式的运行环境,这里我们需要修改六个配置文件。
进入到 hadoop 文件夹下的 etc/hadoop/ 目录下:
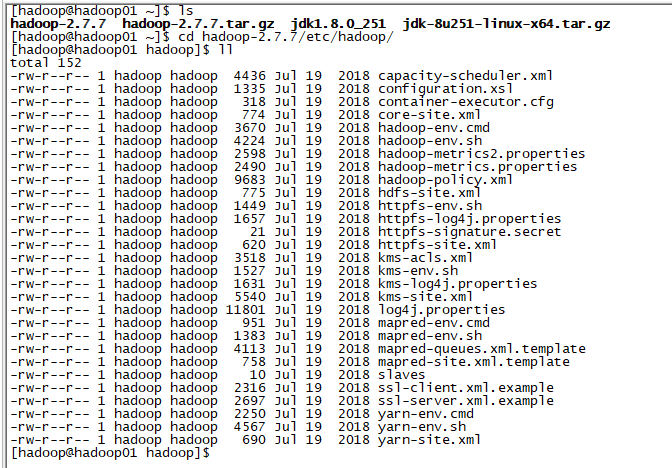
首先修改 hadoop-env.sh 配置文件:
export JAVA_HOME=${JAVA_HOME} => export JAVA_HOME=/home/hadoop/jdk1.8.0_251
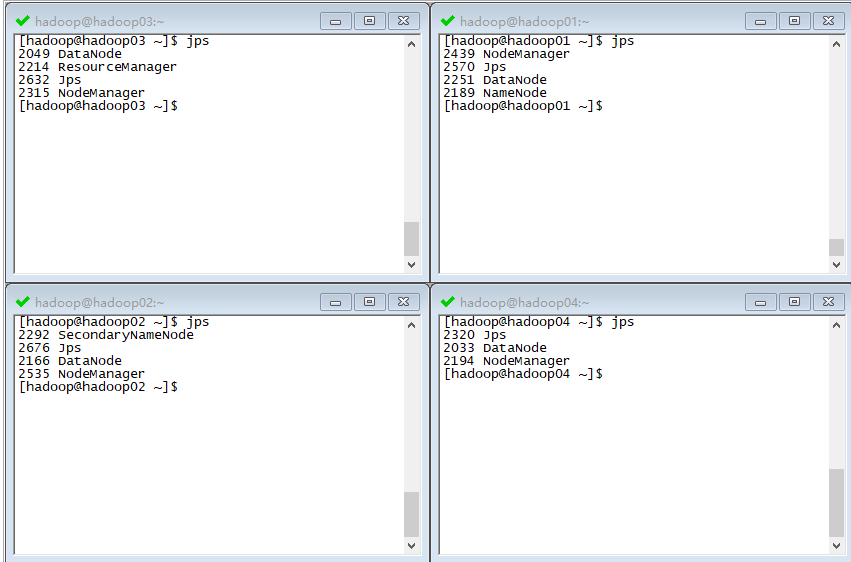
然后我们要做一下集群规划,我的集群规划如下:
| 节点 | hdfs | yarn |
|---|---|---|
| hadoop01 | namenode datanode | nodemanager |
| hadoop02 | datanode secondarynamenode | nodemanager |
| hadoop03 | datanode | resourcemanager nodemanager |
| hadoop04 | datanode | nodemanager |
再修改 core-site.xml 配置文件,添加下面内容到 core-site.xml 文件中:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<description>hdfs 的主节点</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata</value>
<description>修改后的临时目录,一定得配置在有权限的目录下</description>
</property>
再修改 hdfs-site.xml 配置文件,添加下面内容到 hdfs-site.xml 文件中:
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoopdata/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/data</value>
<description>datanode 的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>HDFS 的数据块的副本存储个数</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
<description>secondarynamenode 运行节点的信息,与 namenode 在不同节点上</description>
</property>
再修改 yarn-site.xml 配置文件,添加下面内容到 yarn-site.xml 文件中:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
<description>yarn 的主节点</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
然后修改 mapred-site.xml 配置文件,因为没有 mapred-site.xml 文件,所以先『COPY』出此文件:
cp mapred-site.xml.template mapred-site.xml
添加下面内容到 mapred-site.xml 文件中:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定 mapreduce 跑在 yarn 上</description>
</property>
最后修改 slaves 文件(需将文件内容清空),slaves 配置的是从节点(hadoop01、hadoop02、hadoop03、hadoop04)的信息:
hadoop01
hadoop02
hadoop03
hadoop04
注:不能在前后加空格和回车符。
这一章上面修改的六个配置文件可以先在一台服务器节点上配置好(假设已经在 hadoop01 节点上配置完成),然后传送到其他服务器节点上。
scp -r hadoop-2.7.7 hadoop02:$PWD
scp -r hadoop-2.7.7 hadoop03:$PWD
scp -r hadoop-2.7.7 hadoop04:$PWD
最后所有节点再更新一下 profile:
source /etc/profile
进行格式化
格式化必须在 namenode 的节点上,这里我们设置的 namenode 是在 hadoop01 上:
hadoop namenode -format
启动
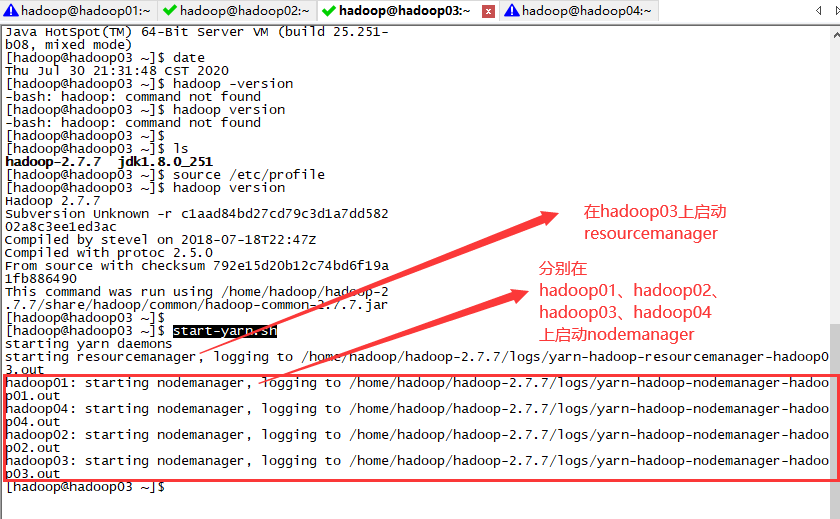
先启动 HDFS,再启动 YARN。
HDFS 的启动在任意节点都可以启动:
start-dfs.sh
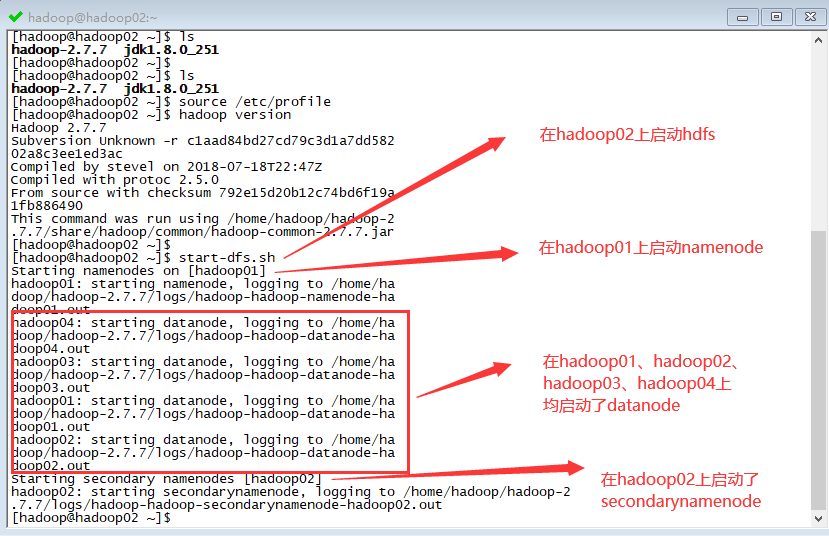
YARN 的启动只能在 YARN 的主节点执行(这里设置的 YARN 的主节点是 hadoop03):
start-yarn.sh
验证
JPS 验证,使用 JPS 查看启动的进程可以发现启动的进程正好对应我们所做的 集群规划:
网页验证:
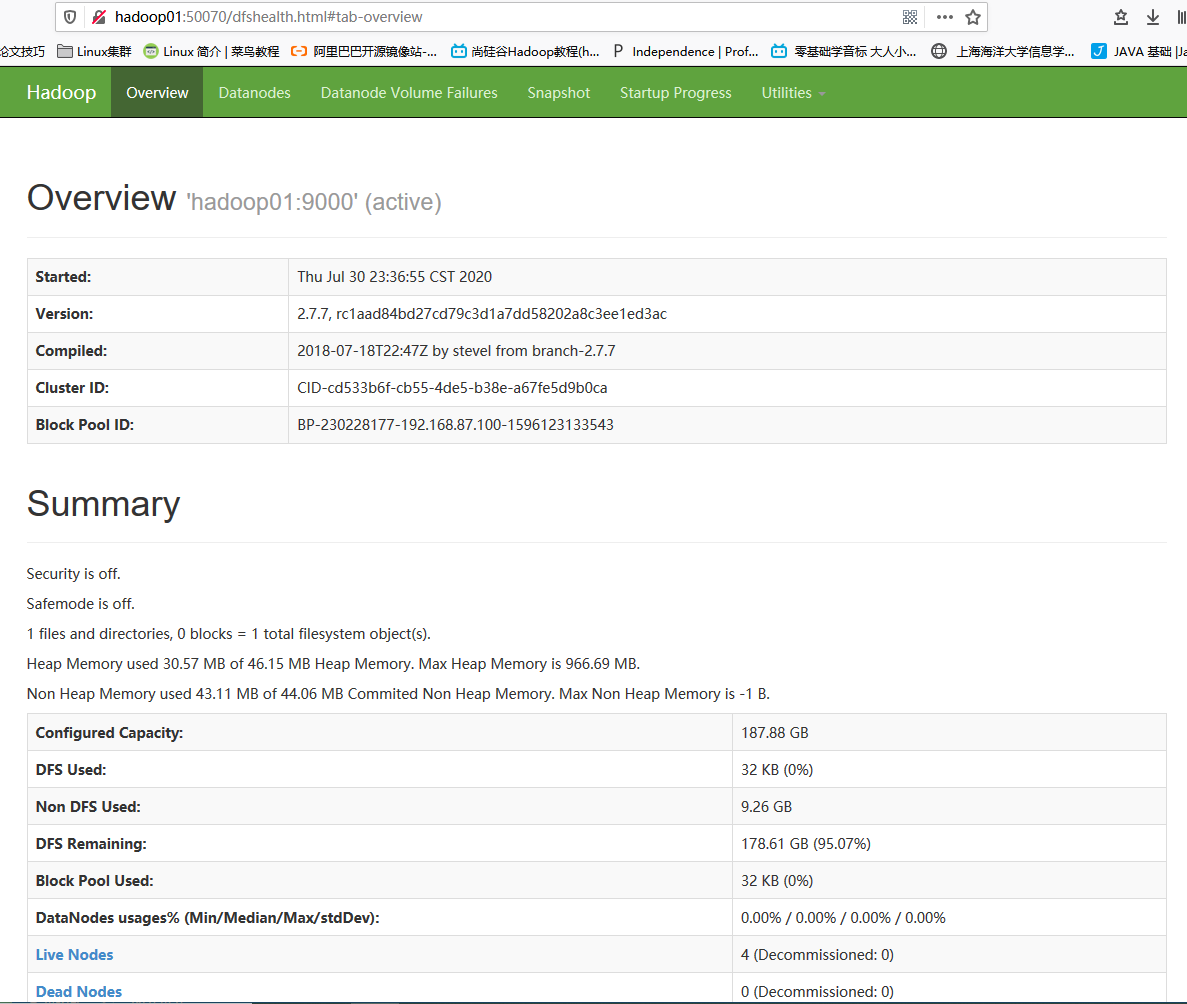
hdfs: hadoop01:50070
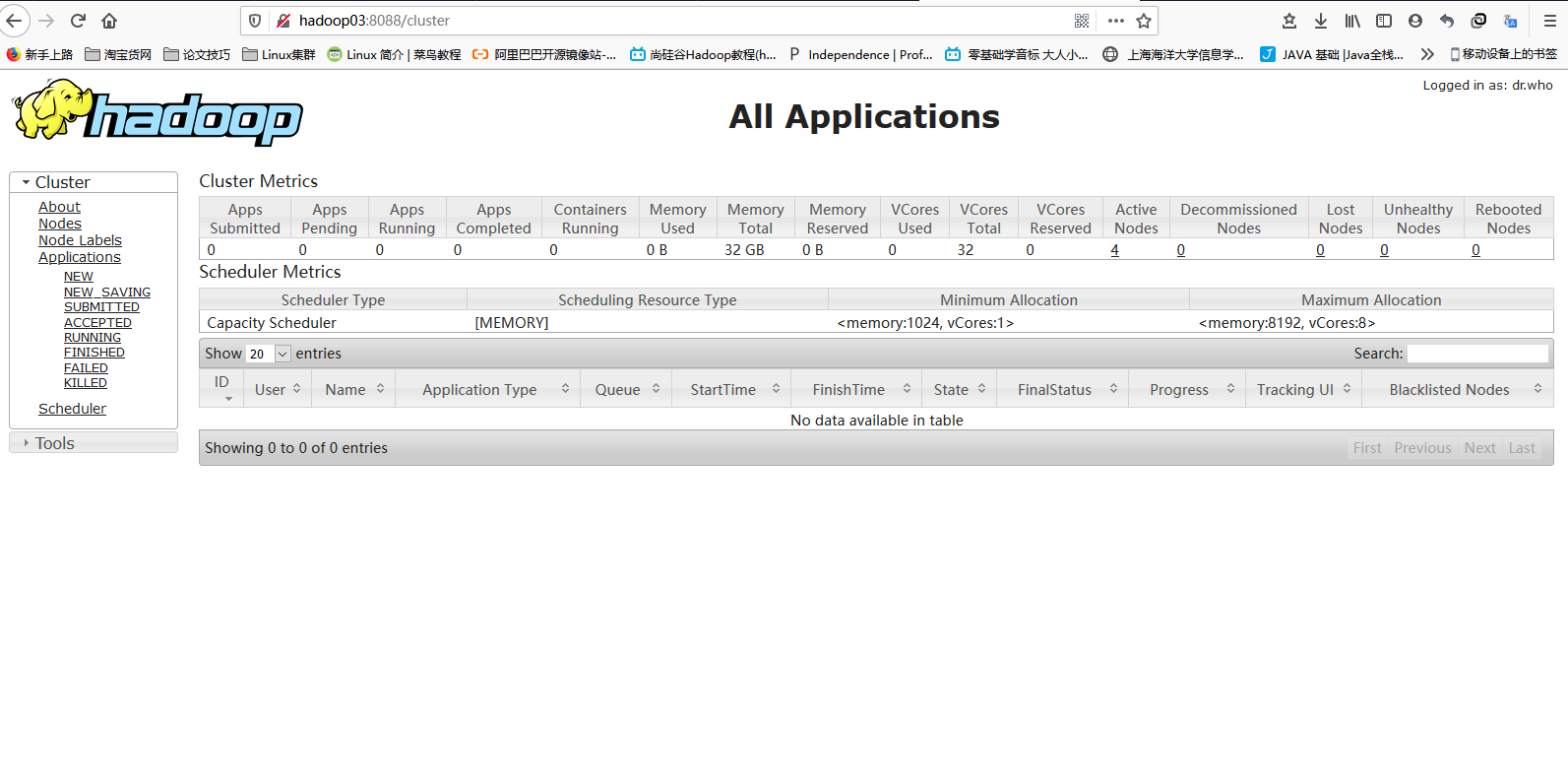
yarn: hadoop03:8088
hadoop01:50070
hadoop03:8088
文档信息
- 本文作者:Bin Tu
- 本文链接:https://plandocheckaction.github.io/2020/07/26/BigData4-EnvironmentSetup/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)