
HDFS 的 四大机制两大核心
HDFS 之所以能够提供高容错性的分布式的数据存储方案,就是因为其中的四大机制和两大核心功能。
四大机制
HDFS 各节点如何保证存储、如何通信就是依赖于 HDFS 的四大机制。
这四大机制分别是:
- 心跳机制:datanode 定期向 namenode 发送「心跳包」,证明自己还活着;
- 安全模式:在集群启动时会进入安全模式,为了防止在集群的启动期间对数据进行操作;
- 机架策略:即副本存放机制;
- 负载均衡:即每个节点的数据百分比差不多。
心跳机制
要实现心跳机制就必须先对集群中的各个节点做时间同步。
我们知道,namenode 的作用就是负责集群上任务的分工,那么如果要做分工就必须知道各个节点的存活状态和各节点自身的信息。
那么在 HDFS 运行的时候,namenode 是如何知道各节点还活着的呢? 答:是通过 datanode 定期向 namenode 发送心跳报告以证明自己还活着。
datanode 会每隔 3s(默认 3s,可以修改)向 namenode 发送一次心跳报告,但当 namenode 在 3s 后没有接收到 datanode 发送的心跳报告时,也不会立即判断 datanode 死了,而是当 namenode 连续 10 次没有收到 datanode 发送的心跳报告时,才会认为此 datanode 可能死亡,这时 namenode 会主动向 datanode 发送一次检查,发送一次检查的时间是 5min(默认 5min,可修改),如果一次检查没有返回信息,这时 namenode 会再进行一次检查,如果还接受不到 datanode 的返回信息,则判断此 datanode 已死亡,所以判断一个 datanode 是否死亡的最长时间是 10min30s。
安全模式
在了解安全模式之前,我们需要知道 HDFS 启动时需要做哪些事情。
HDFS 启动时:
- namenode 启动,namenode 将本机磁盘上的元数据加载到内存中;
- datanode 启动,datanode 向 namenode 发送心跳报告,目的是让 namenode 获取datanode 的存活状况和 datanode 块上的存储信息;
- 启动 secondarynamenode。
集群在启动 HDFS 时(即执行上述三个行为时),不允许外界对集群进行操作,这个时候集群处于安全模式。
注:namenode 启动时,首先会将磁盘上的元数据(抽象目录树、数据和块的映射关系)载入到内存当中,然后 namenode 会接收所有 datanode 的心跳报告,这个心跳报告中除了可以获取 datanode 的生死状况外,还包含数据块的存储位置信息,这时,namenode 就可以获取 datanode 的数据块的存储状况。现在,namenode 节点的内存中的元数据就包含了「抽象目录树」、「数据和块的映射关系」、「数据块存储的位置信息」。
也就是说,集群处于安全模式时主要是在加载元数据和获取 datanode 的心跳报告。当 namenode 接收到集群中 99% 的 datanode 的心跳报告时即会自动退出安全模式。
如果集群处于维护或升级的时候,我们也可以手动将集群设置为安全模式状态:
# 进入安全模式
hdfs dfsadmin -safemode enter
# 离开安全模式
hdfs dfsadmin -safemode leave
# 获取安全模式的状态(是否进入了安全模式,进入了安全模式为 ON,离开了为 OFF)
hdfs dfsadmin -safemode get
# 等待安全模式退出
hdfs dfsadmin -safemode wait
在安全模式下,用户可以执行的操作仅为不修改元数据的操作,例如目录和文件的查询、文件内容的查看、文件的下载等,这些操作均不涉及元数据的增删改。
机架策略
机架感知策略就是 HDFS 的副本存放策略,即副本块是按由近到远的顺序存储在集群上的。
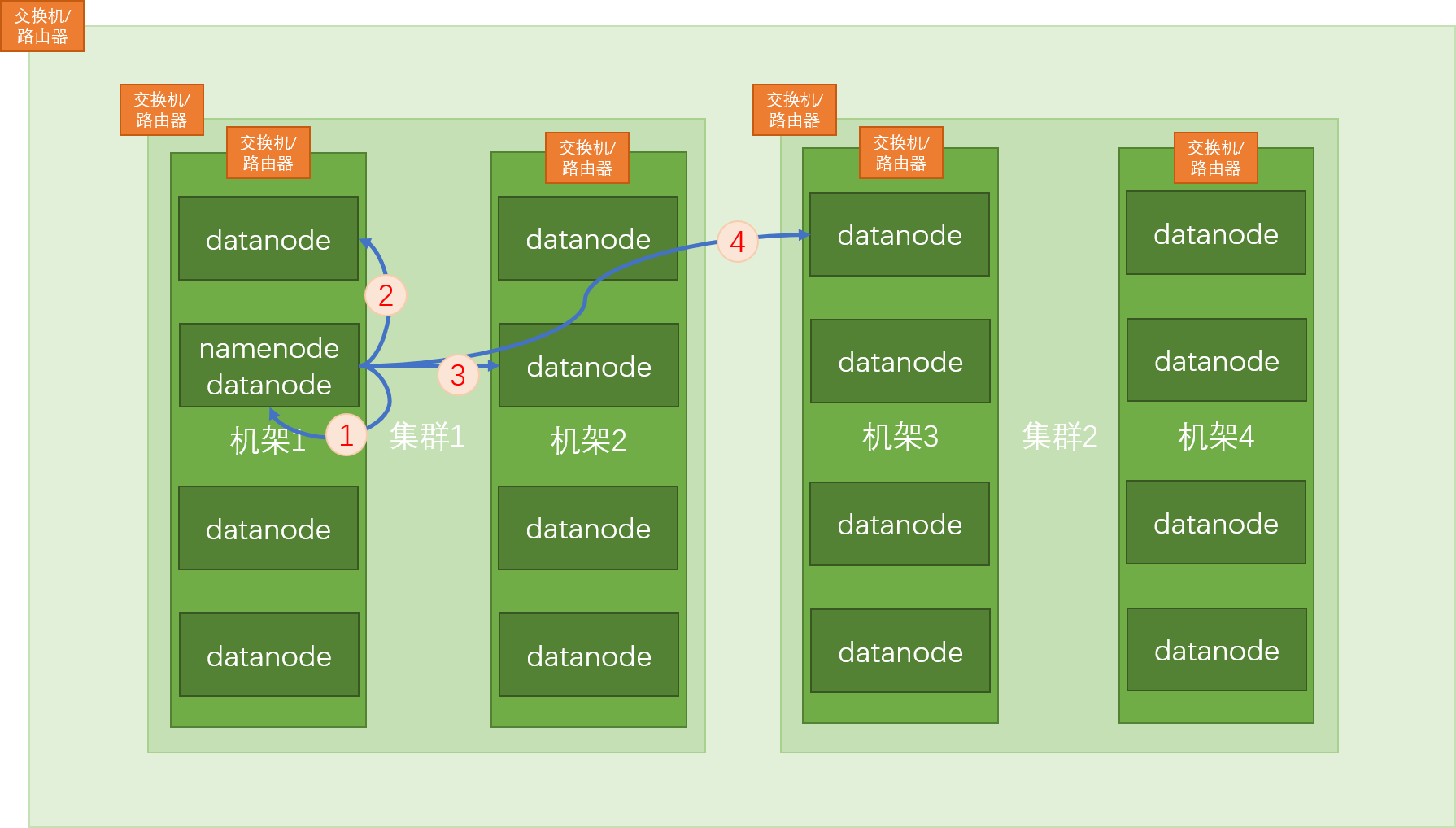
如上图,假设在 namenode 的节点上上传文件到 HDFS,因为此节点也是 datanode 节点,所以第一份副本块会存放到本身机器上,然后第二份副本块存放在离自己通信距离最近的 datanode 节点上,第三份副本块放在不同机架但同一集群的 datanode 节点上,第四份副本块放在不同集群不同机架的 datanode 节点上。
注:在 namenode 节点上传不是必须的,即在任意 datanode 节点上传均先将副本块存储在本身机器上,然后按照由近及远进行保存,且为了防止某一整体挂掉/宕机/死亡,所以存放副本块时要按照如上方式进行存储。
注:节点之间的通信就是依靠交换机进行的。
负载均衡
顾名思义,即在每个 datanode 节点上所存储的数据的百分比相差不大。
注:负载均衡没有绝对的均衡。
这里的百分比指的是已存储数据的量和此 datanode 节点的存储容量的比值。
假设有一个 6TB 的文件要分散存储在剩余存储容量为 8TB 和 4TB 的 datanode 节点上,如果两个节点分别存 3TB,则这不叫作负载均衡,负载均衡应该是 8TB 节点存 4TB,4TB 节点存 2TB,即均达到 4TB/8TB=50%=2TB/4TB。
值得注意的是,当经常在同一客户端所在的节点上传文件时,会因为机架感知策略导致这一客户端所在节点存储的数据较多,当然集群本身会有一个自动的负载均衡的操作,只不过这个自动的负载均衡的操作比较慢(默认 1M/s,可修改)。
所以集群自动的负载均衡对于集群节点较少的情况下是可以的,但如果集群规模特别大的时候,这时自动负载均衡花费的时间就很长,这个时候就需要我们手动进行负载均衡:
# 在 hadoop/sbin/ 目录下,有一个 start-balancer.sh
start-balancer.sh
# 或者家一个参数,-t 10% 表示任意两节点之间的存储百分比不超过 10% 即认为已经达到负载均衡了
start-balancer.sh -t 10%
注:上面这个手动的负载均衡的命令也不会立即执行,它需要等待 hadoop 集群空闲的时候再去执行。
注:在集群中动态添加一个新的 datanode 节点时发生负载均衡的频率较高。
两大核心
HDFS 作为一个文件系统,其两大核心功能就是上传和下载。
上传
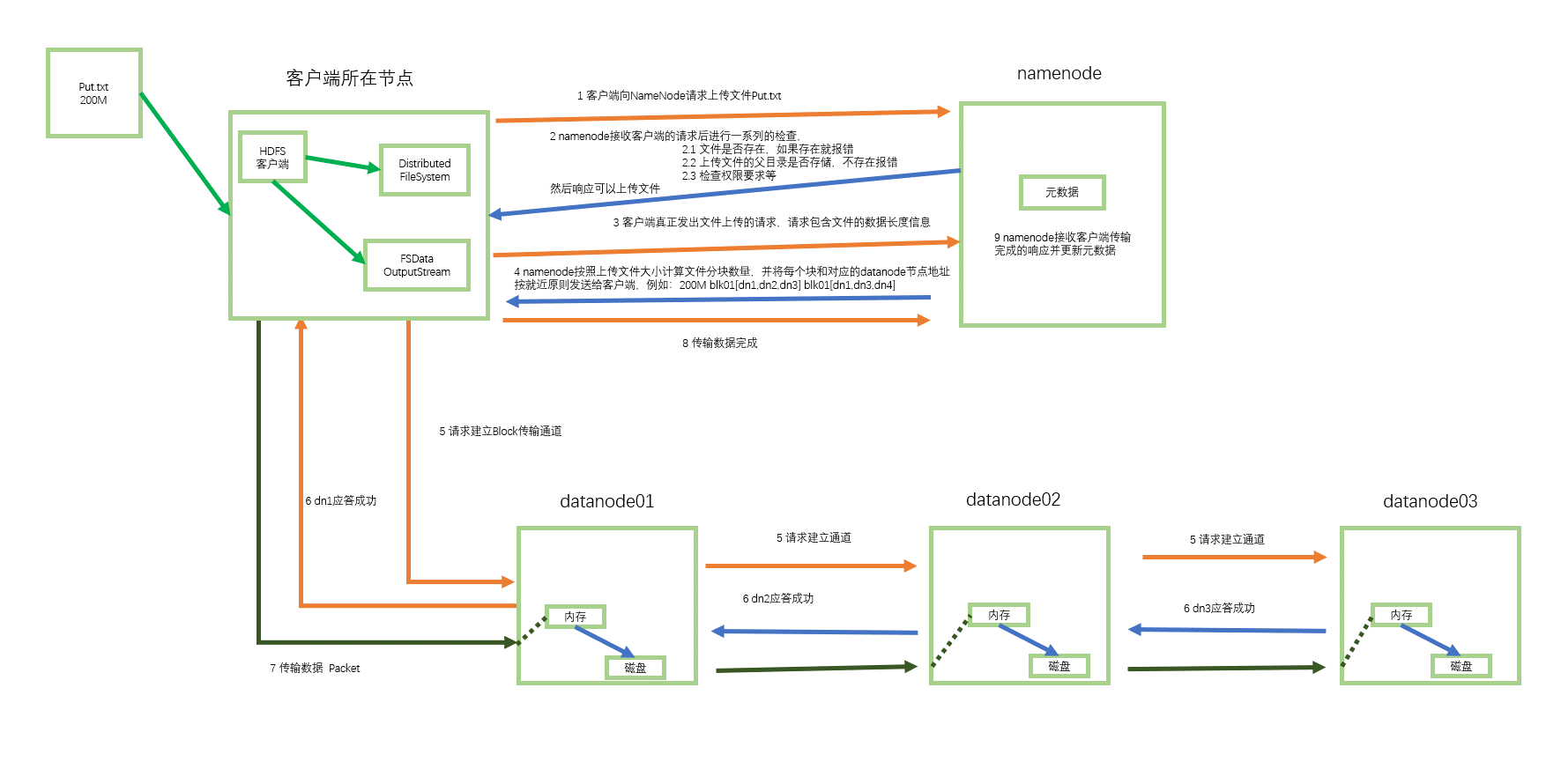
如图,如果将文件 Put.txt 上传到 HDFS 上,首先要开启一个客户端,客户端开启一个分布式文件系统和文件输出流用于将数据写入到 datanode 中,需要注意的是,如果当其中一个或多个 datanode 无法建立通信管道,但只要目前的通信管道可以满足所传输的最小副本数时(默认最小副本数为 1),则可继续传输,namenode 具有动态调节副本块个数的容错机制,如果所有节点都不能建立通信管道,则客户端会重新要求 namenode 发送三个新的 datanode 节点。
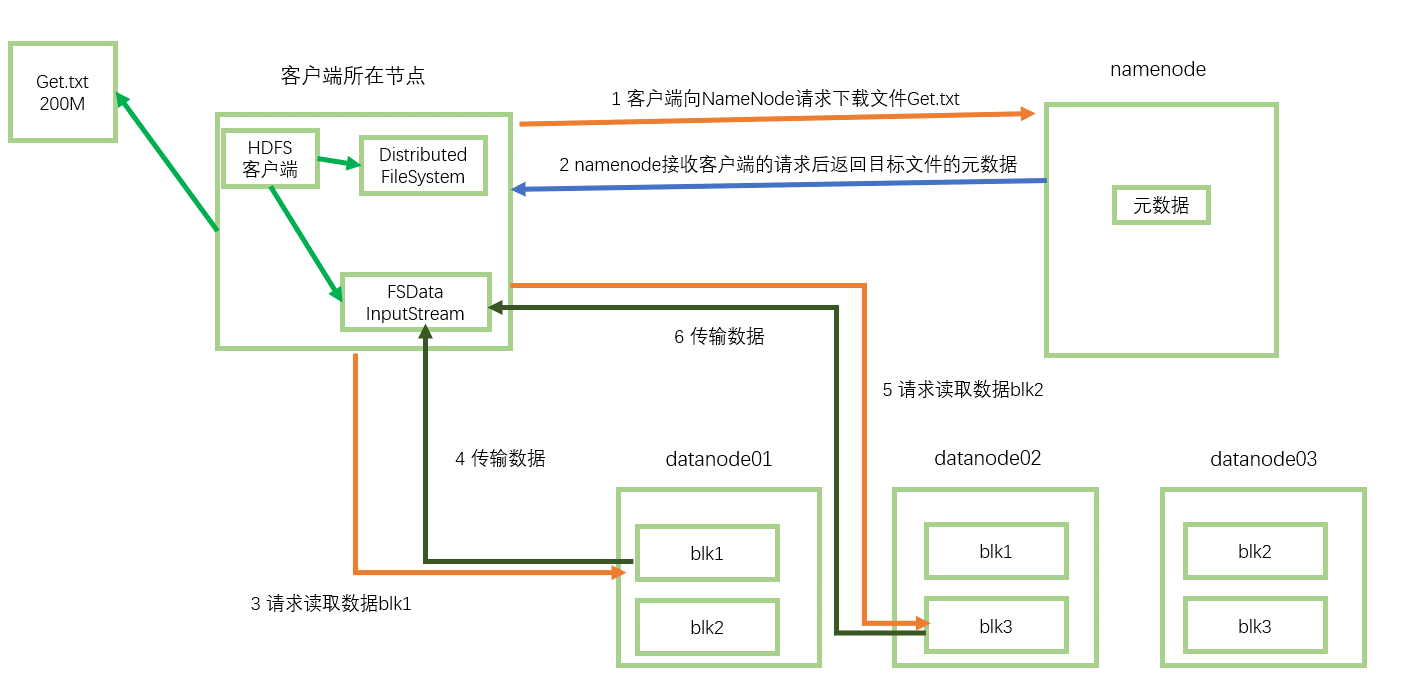
下载
文档信息
- 本文作者:Bin Tu
- 本文链接:https://plandocheckaction.github.io/2020/08/10/BigData8-HDFS42/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)