
Suffle
一般,我们把 Map 阶段到 Reduce 阶段的这个中间阶段叫做 Suffle 过程,在 Suffle 过程中,我们又可以将其细分为 Map 阶段的 Suffle 过程和 Reduce 阶段的 Suffle 过程。
在 Suffle 过程中,有一个比较重要的角色,叫环形缓冲区,环形缓冲区本质上就是一个内存当中的数组。下面我们讲一下这个环形缓冲区在 Suffle 过程中起到一个什么角色。
环形缓冲区
maptask 的结果会先输出到环形缓冲区中,即在 map() 方法中,调用一次 context.write() 就往环形缓冲区写出一次,所以 maptask 会频繁的进行写出操作,因为需要进行频繁写出操作,如果直接将 maptask 的输出结果直接写到磁盘当中,会频繁调用磁盘 IO,这会极大降低程序的效率,所以在 map 端的 suffle 过程中,maptask 的输出结果会先写到内存缓冲区中(即我们所要探讨的环形缓冲区),然后再由缓冲区积累到一定的数据后(默认数据达到总环形缓冲区大小的80%触发一次磁盘写入),统一调用一次磁盘 IO 去写入更多的数据。
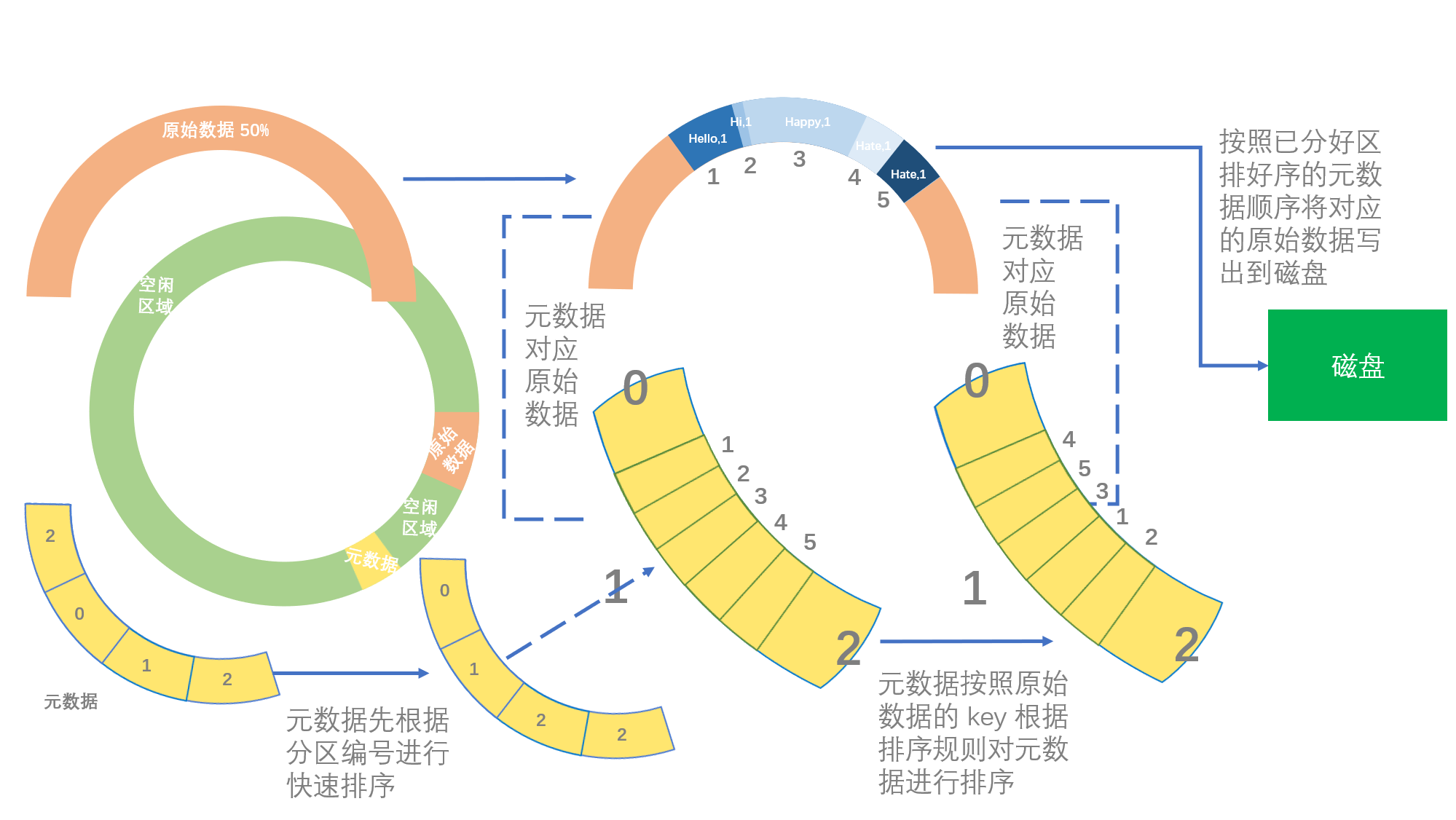
环形缓冲区中存放了两部分内容,一部分是 Map 端写出的原始数据,另一端是记录原始数据的数据,我们称为元数据,一个元数据对应一个 context.write() 当中有四部分内容,分别是「原始数据中 Key 的起始位置」、「原始数据中 Value 的起始位置」、「Value 的长度」和「分区信息」。值得注意的是,由于原始数据的长度不是固定的,所以我们需要元数据来标明原始数据的 key 和 value 在环形缓冲区的位置和长度以及原始数据属于哪个分区。
注:元数据的长度固定,为 16*4 = 64 字节。
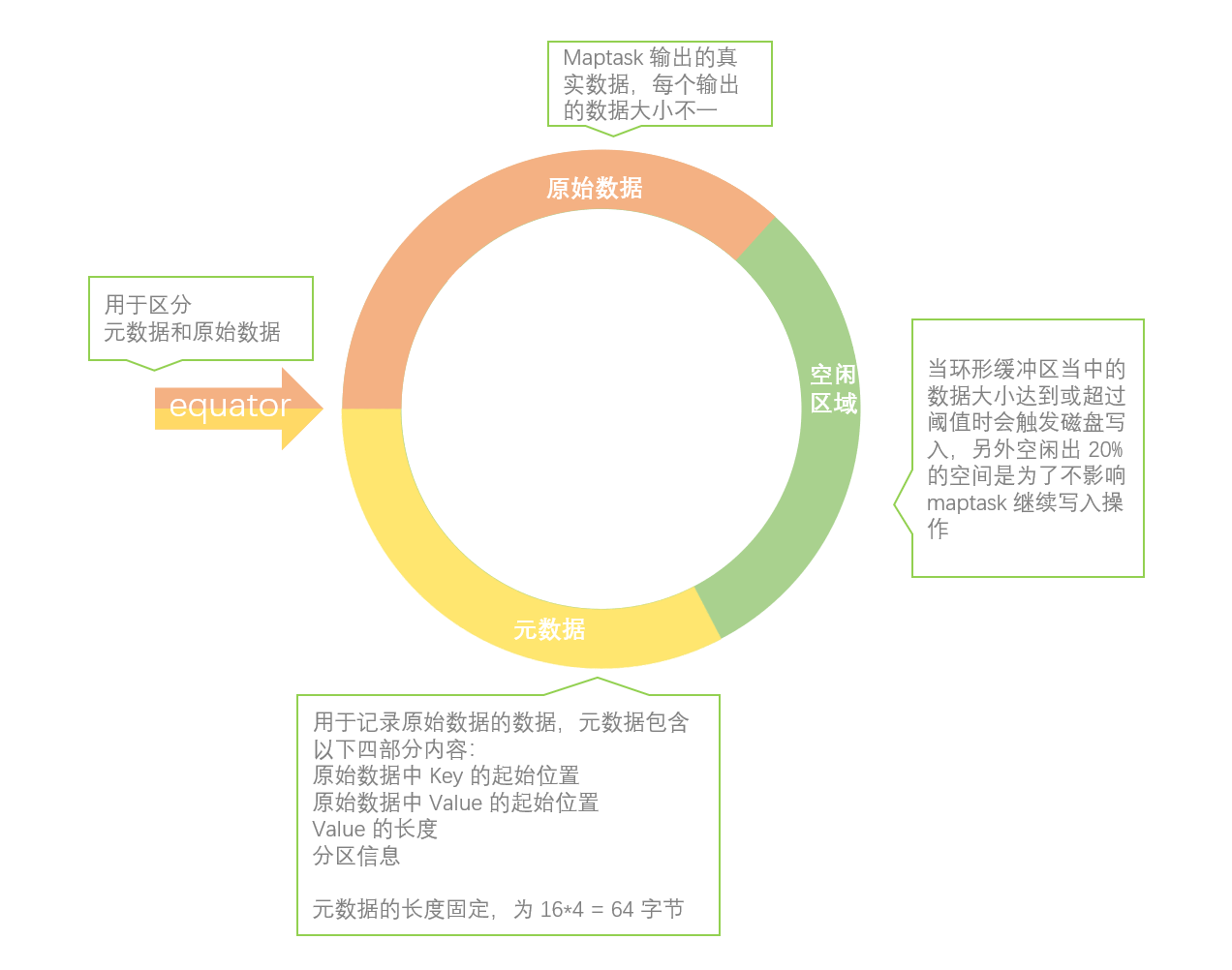
其实环形缓冲区本质上就是一个逻辑上首尾相连的字节数组。
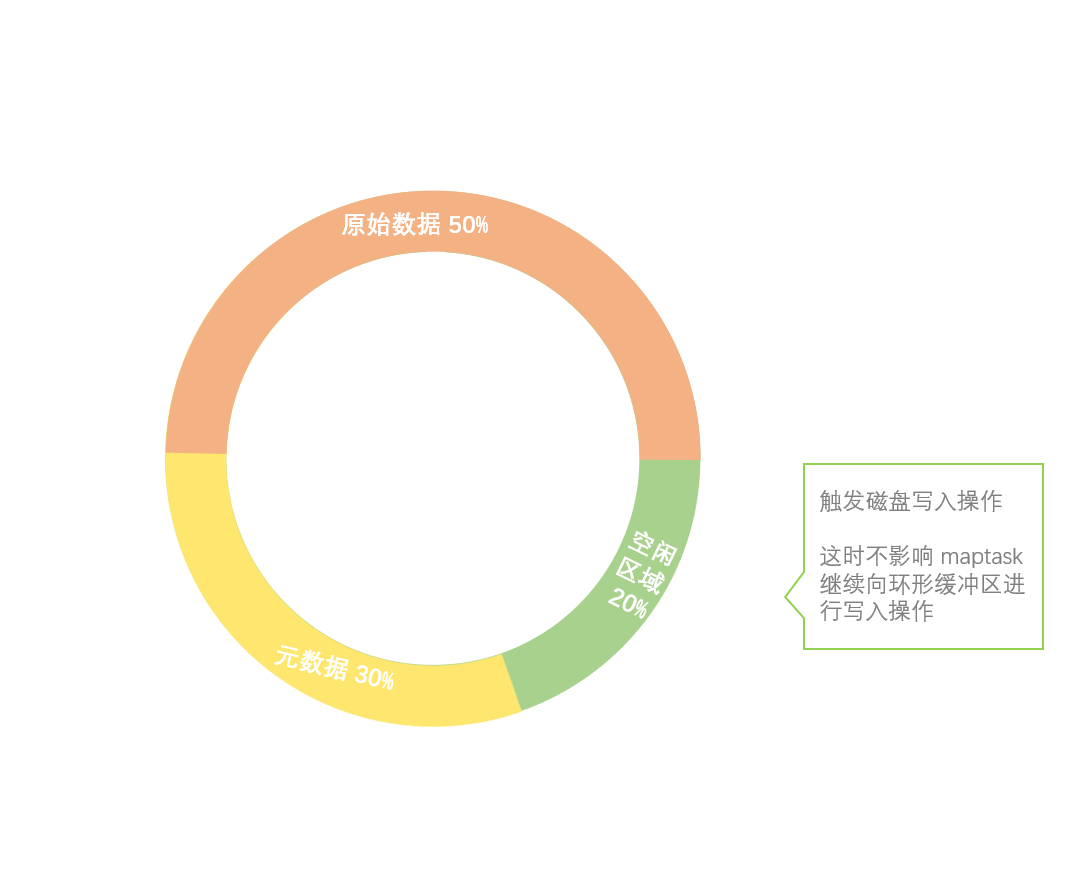
环形缓冲区的默认大小为 100M,缓冲区会设置一个写入的阈值(80%),达到或超过阈值时会触发磁盘写入的操作,写入磁盘后环形缓冲区会进行重新清空,以便有足够的空间接收 maptask 新的输出结果。
设置阈值的作用是在达到阈值后,数据写出到磁盘的同时,maptask 还可以继续向环形缓冲区写入数据。
注:如果在数据写入到磁盘的过程中,另外剩余的空闲空间也被写满,则会进入阻塞状态,阻塞到以上数据全部写入磁盘、空间释放。
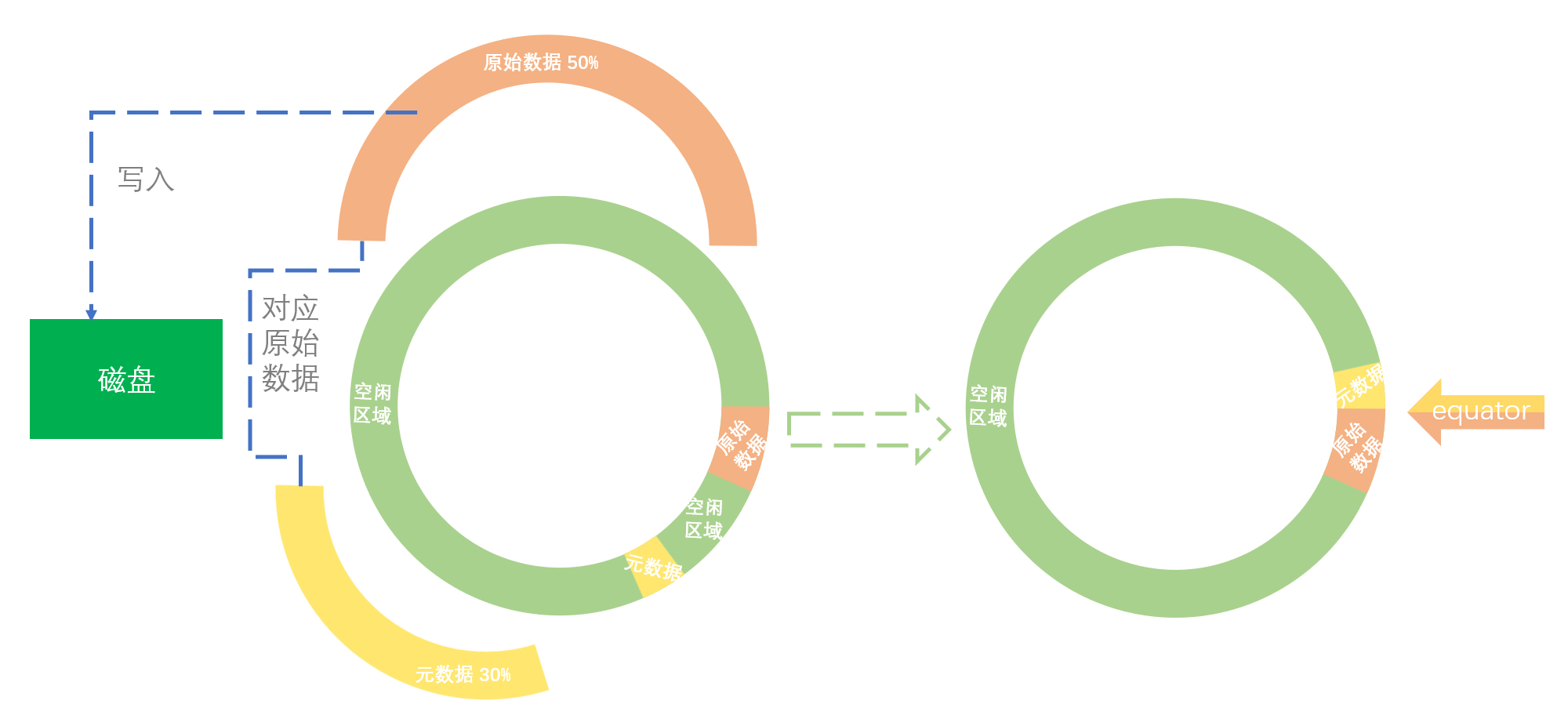
由于缓冲区是根据一个数组位置向两边写的,又因为所以我们写入缓冲区的数据量达到其阈值时会被溢写到磁盘,所以我们每次溢写后就要改变元数据和原始数据的起始写入位置,所以也就出现了需要标明起始位置的属性参数(equator)。
Map 阶段的 Suffle 过程
假设我们有一个 500M 的文件数据存放在 HDFS 上,这个文件的四个切片分别存放在其分布式集群的三个节点上。
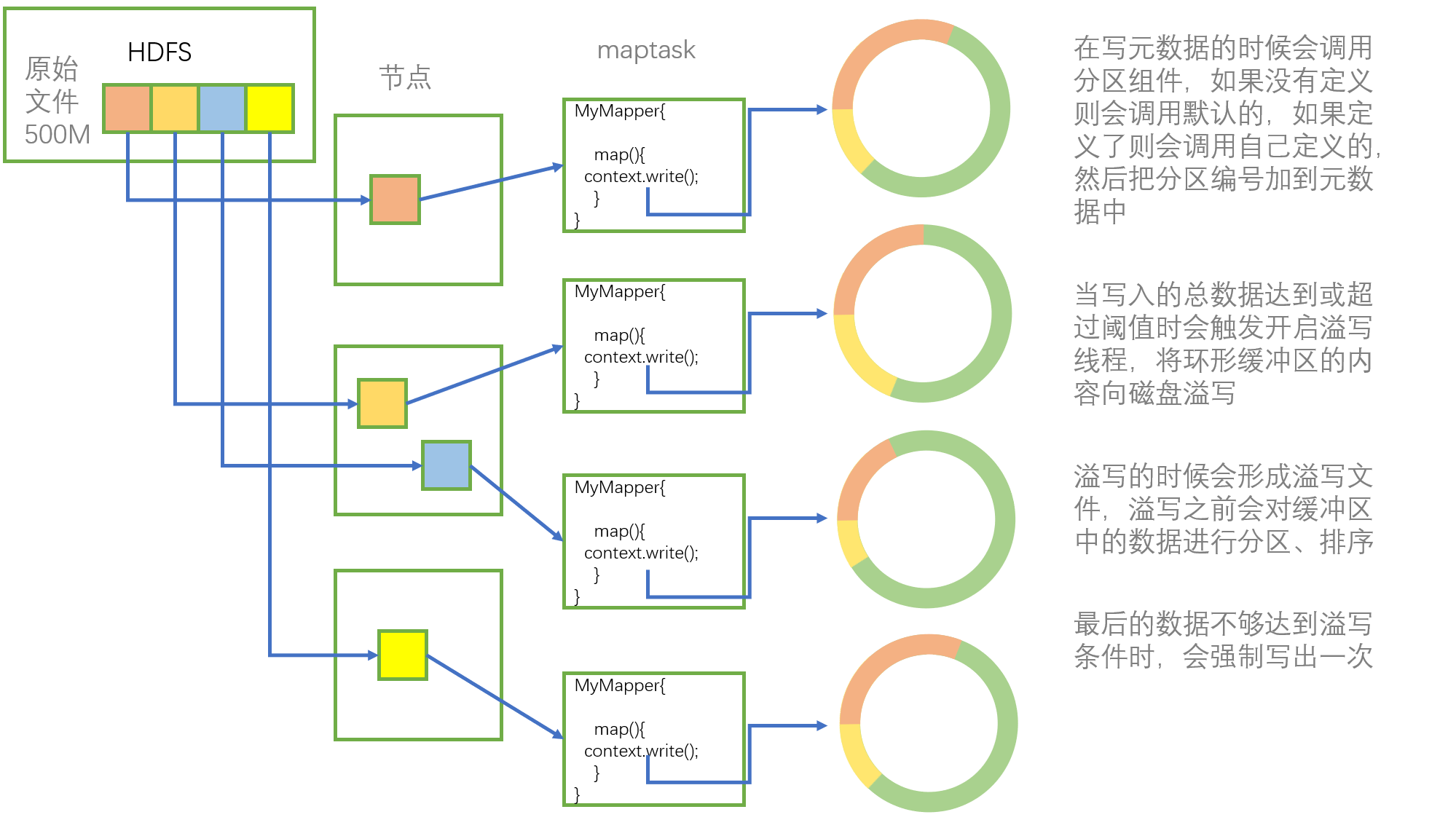
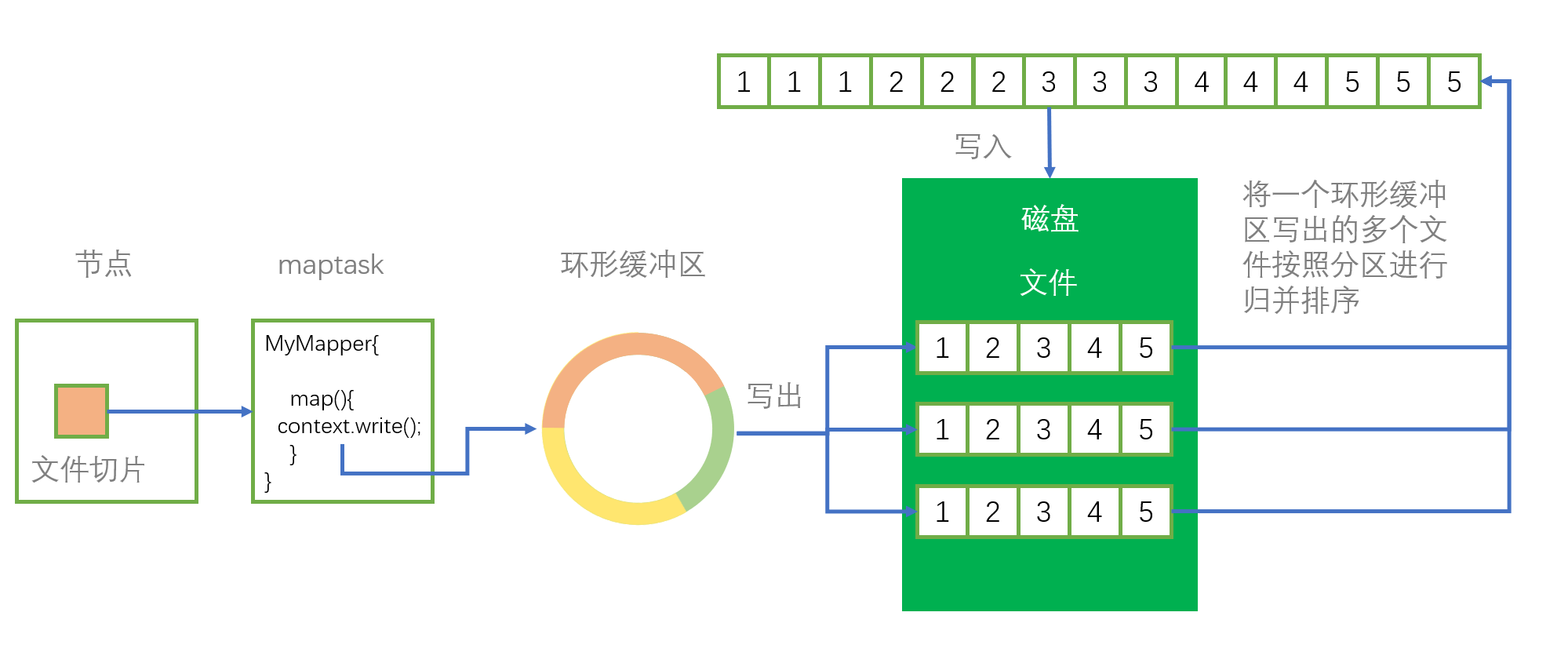
当启动 MapReduce 程序的时候,默认一个切片(128M)开启一个 maptask 进程,所以则会开启四个 maptask 进程,每个 maptask 最后都写入到各自的环形缓冲区中、互不干扰。
当每个 maptask 向环形缓冲区写入直到触发溢写操作时,环形缓冲区会向磁盘进行溢写,在向磁盘进行溢写之前,环形缓冲区会先将里面的内容进行分区、排序,分区排序均按照快速排序进行。
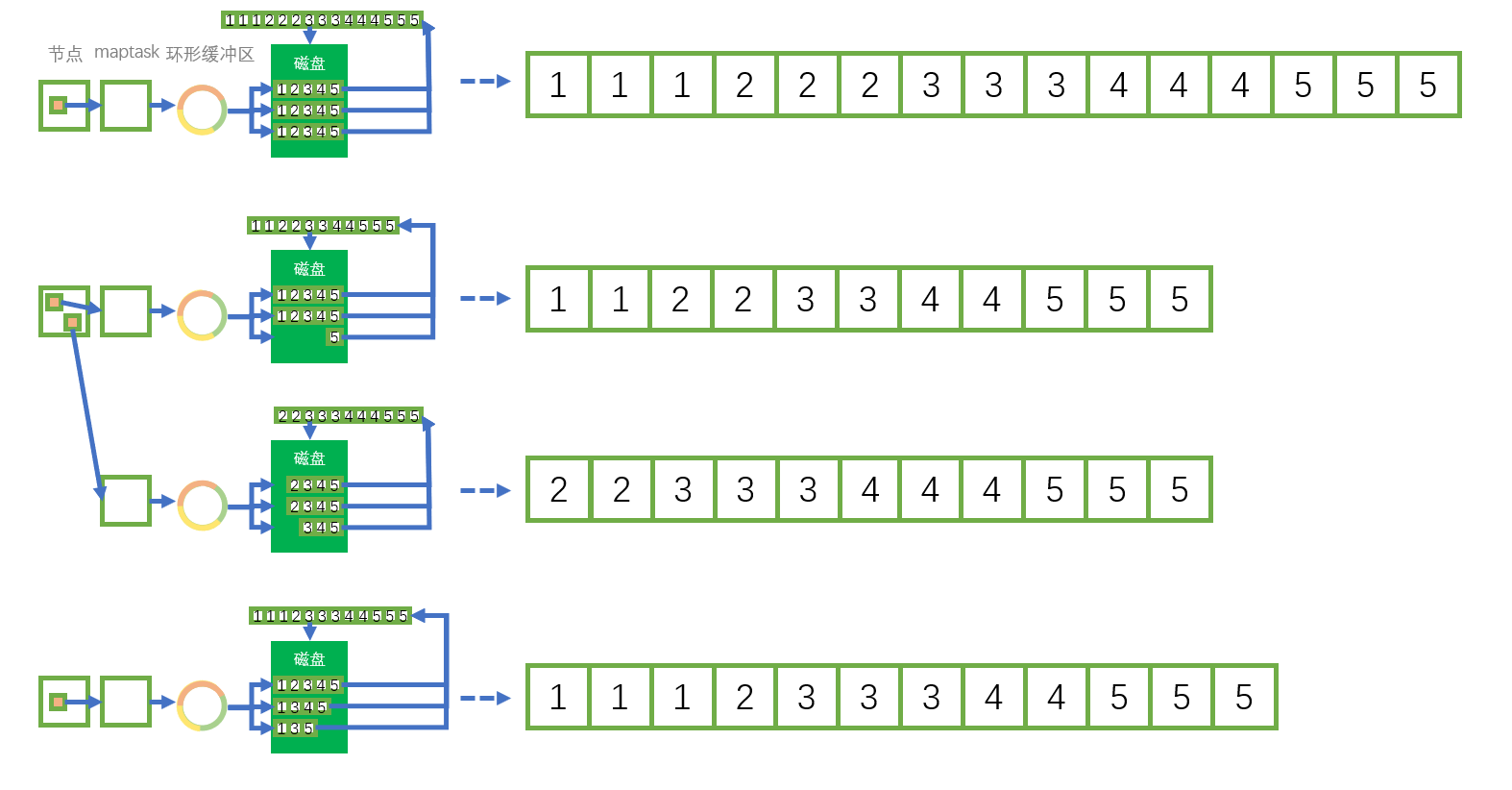
每个 maptask 的写出一般会导致环形缓冲区多次溢写,从而产生多个溢写文件,这些溢写文件均已经分好区排好序了,由于 Reduce 阶段是接收一整个文件作为输入,所以这多个溢写文件还要再进行一次合并,这次的合并采用的是归并排序的算法。
由此 Map 端的 Suffle 过程就结束了,其中每个数据总共进行了两次快速排序(分区、分区内排序)和一次归并排序(溢写文件合并)。
Reduce 阶段的 Suffle 过程
Reduce 端的 Suffle 过程就比较简单了,由上我们可以知道,四个切片启动了四个 maptask,最后生成四个合并后的溢写文件,合并后的溢写文件内部已分好区排好序了。
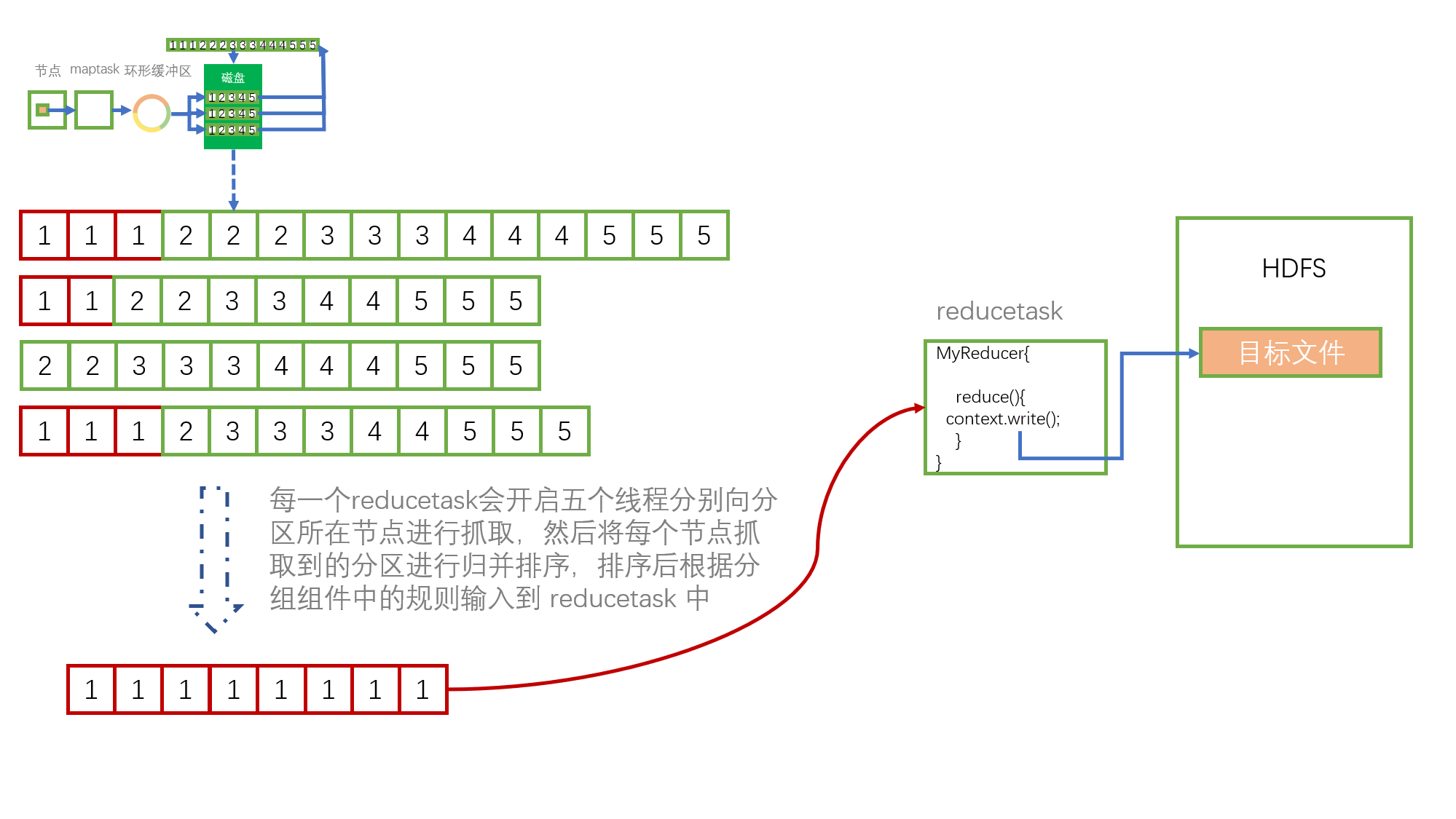
当 maptask 全部结束后,每一个 reducetask 会开启五个线程进行数据抓取,数据的抓取按照分区进行。
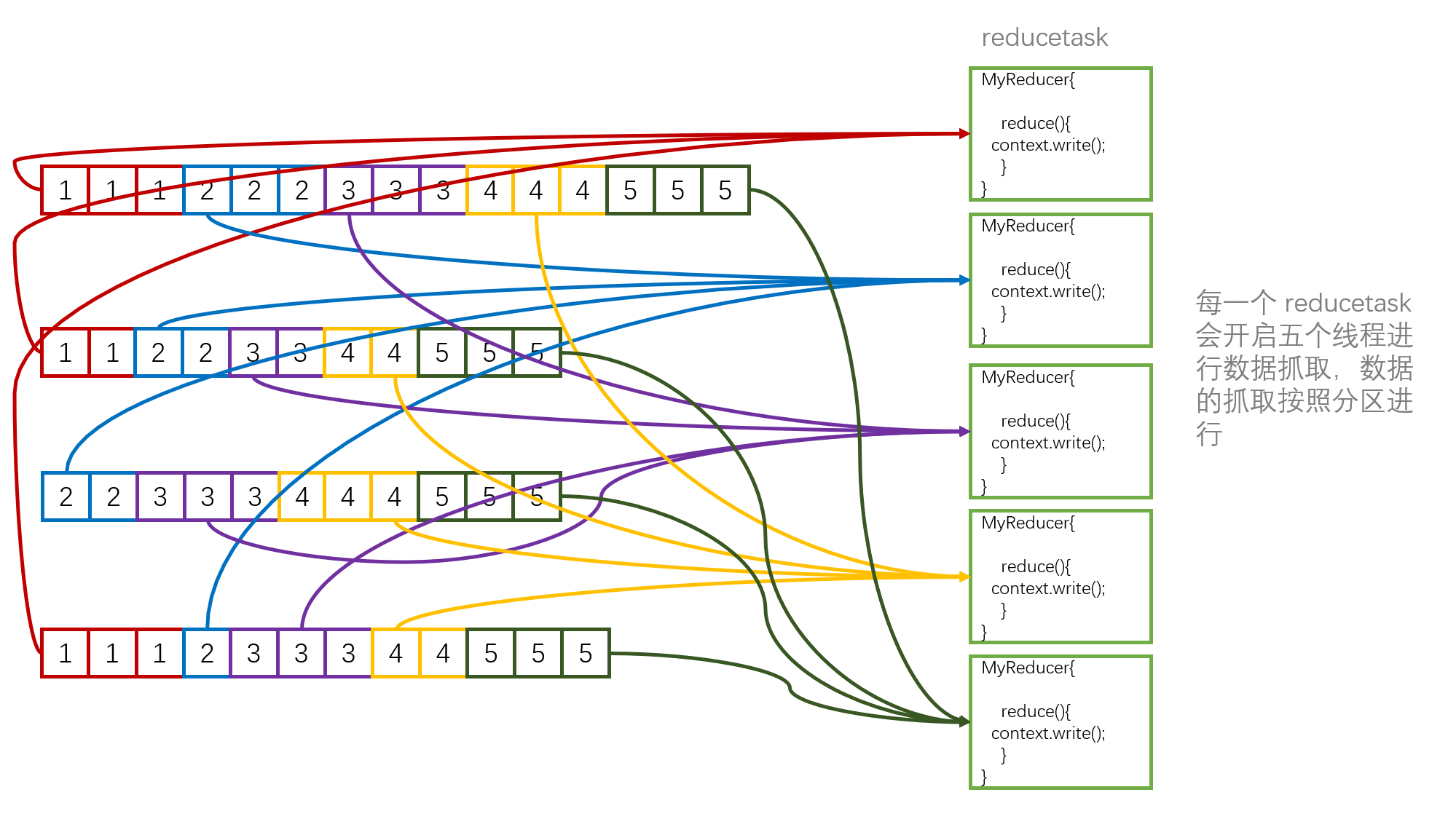
假设以下这个 redecetask 是处理分区为 1 的数据,则此 redecetask 会开启线程去抓取这些包含有分区 1 的数据,然后再将他们合并一次,此次合并也是使用归并排序,然后再将合并后的文件根据分组组件的规则发送给 redecetask 作为输入,最后 redecetask 中的 context.write() 将最终的结果输出到 HDFS 上。
文档信息
- 本文作者:Bin Tu
- 本文链接:https://plandocheckaction.github.io/2020/09/07/BigData14-MapReduceSuffle/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)